我想绘制一个混淆矩阵来可视化分类器的性能,但它只显示标签的数量,而不是标签本身:
from sklearn.metrics import confusion_matrix
import pylab as pl
y_test=['business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business']
pred=array(['health', 'business', 'business', 'business', 'business',
'business', 'health', 'health', 'business', 'business', 'business',
'business', 'business', 'business', 'business', 'business',
'health', 'health', 'business', 'health'],
dtype='|S8')
cm = confusion_matrix(y_test, pred)
pl.matshow(cm)
pl.title('Confusion matrix of the classifier')
pl.colorbar()
pl.show()
如何将标签(健康、业务等)添加到混淆矩阵中?
最佳答案
更新:
在 scikit-learn 0.22 中,有一个新功能可以直接绘制混淆矩阵(但是,该功能在 1.0 中已弃用,将在 1.2 中删除)。
查看文档:sklearn.metrics.plot_confusion_matrix
旧答案:
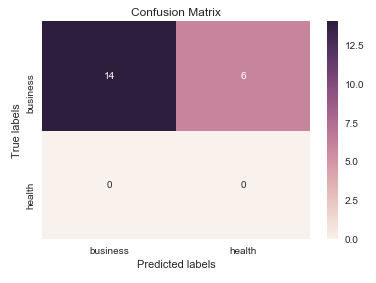
我认为值得一提的是 seaborn.heatmap 的使用在这里。
import seaborn as sns
import matplotlib.pyplot as plt
ax= plt.subplot()
sns.heatmap(cm, annot=True, fmt='g', ax=ax); #annot=True to annotate cells, ftm='g' to disable scientific notation
# labels, title and ticks
ax.set_xlabel('Predicted labels');ax.set_ylabel('True labels');
ax.set_title('Confusion Matrix');
ax.xaxis.set_ticklabels(['business', 'health']); ax.yaxis.set_ticklabels(['health', 'business']);
关于python - sklearn 绘制带有标签的混淆矩阵,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/19233771/