我正在使用这个给定的数据集来解决我的论文问题:
x<- cbind(c(1,2,3,4,5,6,7,8,9,10,11,12,13))
y <- cbind(c(0.37, 0.25, 0.23, 0.24, 0.32, 0.23, 0.24, 0.26, 0.24, 0.26, 0.27, 0.27))
df <- data.frame('x' = x, 'y' = y)
我想拟合这两个模型 y = a + exp(b + (c*x))。我问聊天 GPT,答案让我很困惑。它告诉我尝试用数据 df 进行线性回归,并使用截距作为起始值 a,使用 x 作为起始值 b。
实际上如何确定 nls 中的初始值的正确方法或最佳方法?尤其是我的数据和模型?
我尝试使用数据 df 执行线性回归,并使用截距作为起始值 a,使用 x 作为起始值 b。对于起始值,假定 c 与 b 相等。
m1 <- nls(y ~ model_func1(x, a, b, c), data = df , start = list(a = -0.003033, b=0.284778, c=0.284778), trace = T)
summary(m1)
但我总是遇到这个错误
Error in nls(y ~ model_func1(x, a, b, c), data = df, :
singular gradient
最佳答案
正如评论中提到的,x 和 y 具有不同的长度,因此 data.frame(...) 语句将不起作用。此外,我们不需要cbind。假设 x 定义是错误的,请使用下面所示的输入定义。问题中使用的起始值可以工作,但为每个参数使用起始值 1 也可以,所以让我们使用它。 (问题中的起始值稍微好一些,因为它们在 26 次迭代后导致收敛,而对于全 1 则为 29 次迭代,但全 1 似乎更简单。)尽管这会导致收敛,但绘图显示它与第一点不太吻合,因此我们尝试显示了 lm 模型,请注意它很容易拟合并且具有较低的偏差(=残差平方和),并且只需要 2 个参数,而不是原始模型中的 3 个参数。
# input
y <- c(0.37, 0.25, 0.23, 0.24, 0.32, 0.23, 0.24, 0.26, 0.24, 0.26, 0.27, 0.27)
df <- data.frame(x = seq_along(y), y)
fo <- y ~ a + exp(b + c * x)
st <- list(a = 1, b = 1, c = 1)
fm <- nls(fo, df, start = st)
deviance(fm)
## [1] 0.01866574
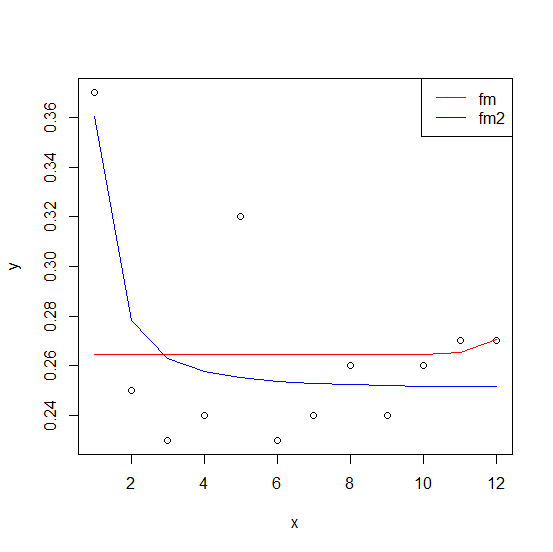
通过反复试验,我们发现该模型具有更好的偏差,即残差平方和更低,即 0.008170078 与 0.01866574,并且在最后显示的图中看起来也更合理。
# alternate model
fm2 <- lm(y ~ I(1/x^2), df)
deviance(fm2)
## [1] 0.008170078
# graphics
plot(df)
lines(fitted(fm) ~ x, df, col = "red")
lines(fitted(fm2) ~ x, df, col = "blue")
legend("topright", c("fm", "fm2"), lty = 1, col = c("red", "blue"))
关于r - 确定 rstudio 中 nls 函数的最佳初始值,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/76599992/