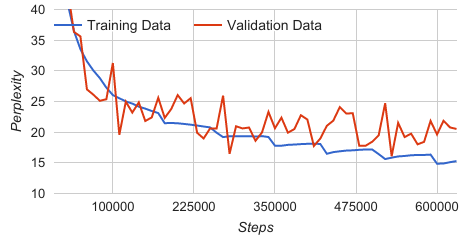
我正在使用 LSTM 和 tensorflow 的翻译模型训练 session 代理。我使用批量训练,导致每个纪元开始后训练数据的复杂度显着下降。这种下降可以通过我将数据读取到批处理中的方式来解释,因为我保证训练数据中的每个训练对在每个时期都被处理一次。当新的纪元开始时,模型在前一个纪元中所做的改进将在再次遇到训练数据时显示出其 yield ,在图中表示为下降。其他批量方法(例如 tensorflow 翻译模型中使用的方法)不会导致相同的行为,因为它们的方法是将整个训练数据加载到内存中,并从中随机选取样本。
脚步,困惑
- 330000, 19.36
- 340000, 19.20
- 350000, 17.79
- 360000, 17.79
- 370000, 17.93
- 380000, 17.98
- 390000, 18.05
- 400000, 18.10
- 410000, 18.14
- 420000, 18.07
- 430000, 16.48
- 440000, 16.75
(困惑度的一个小片段显示在 350000 和 430000 之间下降。在下降之间,困惑度略有上升)
但是,我的问题是关于下跌后的趋势。从图中可以明显看出,困惑度略有上升(对于步骤 ~350000 之后的每个时期),直到下一次下降。有人可以给出为什么会发生这种情况的答案或理论吗?
最佳答案
这是典型的过度拟合。
关于machine-learning - 每次显着下降之间困惑度计算都会上升,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/44343718/