我正在使用SVR,并使用此resource。一切都很清晰,具有ε密集损失功能(如图)。预测自带管,用于覆盖大多数训练样本并使用支持向量来概括范围。

然后我们有了这个解释。 This can be described by introducing (non-negative) slack variables , to measure the deviation of training samples outside -insensitive zone.我在外部理解了这个错误,但是不知道如何在优化中使用它。有人可以解释一下吗?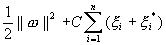
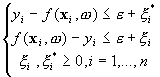
在本地来源。我正在尝试实现没有库的非常简单的优化解决方案。这就是我的损失功能。
import numpy as np
# Kernel func, linear by default
def hypothesis(x, weight, k=None):
k = k if k else lambda z : z
k_x = np.vectorize(k)(x)
return np.dot(k_x, np.transpose(weight))
.......
import math
def boundary_loss(x, y, weight, epsilon):
prediction = hypothesis(x, weight)
scatter = np.absolute(
np.transpose(y) - prediction)
bound = lambda z: z \
if z >= epsilon else 0
return np.sum(np.vectorize(bound)(scatter))
最佳答案
首先,让我们看一下目标函数。第一个术语1/2 * w^2(希望此站点具有LaTeX支持,但这足够了)与SVM的余量相关。在我看来,您链接的文章并不能很好地解释这一点,并称其为描述“模型的复杂性”的术语,但也许这不是解释它的最佳方法。最小化此术语可最大化裕度(同时仍能很好地表示数据),这是使用SVM进行回归的主要目标。
警告,数学运算繁重的解释:出现这种情况的原因是,在最大化边距时,您想在边距上找到“最远的”非离群点并最小化其距离。将此最远的点设为x_n。我们想找到它与平面d的欧几里得距离f(w, x) = 0,我将其重写为w^T * x + b = 0(其中w^T只是权重矩阵的转置,以便我们可以将两者相乘)。为了找到距离,让我们首先对平面进行归一化,使|w^T * x_n + b| = epsilon可以进行WLOG,因为w仍然能够形成形式为w^T * x + b= 0的所有可能的平面。然后,让我们注意w垂直于平面。如果您对平面进行了大量处理(特别是在矢量微积分中),这是显而易见的,但是可以通过在平面x_1和x_2上选择两个点,然后注意w^T * x_1 + b = 0和w^T * x_2 + b = 0来证明。将两个方程式相减得到w^T(x_1 - x_2) = 0。由于x_1 - x_2只是严格在平面上的任何矢量,并且其与w的点积为0,因此我们知道w垂直于平面。最后,为了实际计算x_n与平面之间的距离,我们采用由x_n'和平面x'上的某个点形成的矢量(矢量将为x_n - x',并将其投影到矢量< cc>。这样做,我们得到w,可以将其重写为d = |w * (x_n - x') / |w||,然后在内部加减d = (1 / |w|) * | w^T * x_n - w^T x'|以获得b。请注意,d = (1 / |w|) * | w^T * x_n + b - w^T * x' - b|是w^T * x_n + b(来自归一化),并且epsilon为0,因为这只是我们平面上的一个点,因此w^T * x' + b。请注意,在我们找到d = epsilon / |w|且具有x_n的约束条件下,最大化此距离是困难的优化问题,我们可以做的就是将这个优化问题重构为最小化|w^T * x_n + b| = epsilon,但要遵守所附图片中的前两个约束,即1/2 * w^T * w。您可能会认为我已经忘记了松弛变量,而这是正确的,但是当只关注这个术语而忽略第二个术语时,我们现在暂时忽略松弛变量,稍后我将它们带回。这两个优化是等效的ent并不明显,但根本原因在于歧视的界限,您可以自由阅读更多关于歧视的界限(坦率地说,很多数学,我认为这个答案不需要更多)。然后,请注意,将|y_i - f(x_i, w)| <= epsilon最小化与将1/2 * w^T * w最小化相同,这是我们希望得到的期望结果。重型数学的终结
现在,请注意,我们要使边距变大,但不要太大,以至于不能像您提供的图片那样包含嘈杂的离群值。
因此,我们引入第二个术语。为了将裕量降低到合理的大小,引入了松弛变量(我将它们称为1/2 * |w|^2和p,因为我不想每次都键入“ psi”)。这些松弛变量将忽略边际中的所有内容,即,那些对目标无害的点和在回归状态方面“正确”的点。但是,边缘以外的点是异常值,它们不能很好地反映回归,因此我们仅对现有值进行惩罚。那里给出的松弛误差函数相对容易理解,它只是将p*的每个点(p_i + p*_i)的松弛误差相加,然后乘以一个调制常数i = 1,...,N,该常数决定了cc的相对重要性。这两个词。 C的低值表示我们可以接受离群值,因此裕量将变稀并且将产生更多离群值。 C的高值表示我们非常在意是否有余量,因此将增加边距以容纳这些离群值,但会以不太好表示整体数据为代价。
关于C和p的一些注意事项。首先,请注意,它们始终都是p*。图片中的约束说明了这一点,但从直觉上讲也是有意义的,因为应始终将松弛添加到错误中,因此它是肯定的。其次,请注意,如果>= 0,则p > 0,反之亦然,只能在页边的一侧。最后,边距内的所有点的p* = 0和p均为0,因为它们在当前位置处很好,因此不会造成损失。
请注意,通过引入松弛变量,如果您有任何异常值,则您将不需要第一个条件的条件,即p*,因为|w^T * x_n + b| = epsilon将是此异常值,并且您的整个模型将是搞砸了。然后,我们允许将约束更改为x_n。转换为新优化的约束后,我们将从附带的图片(即|w^T * x_n + b| = epsilon + (p + p*))中获取全部约束。 (我在这里将两个方程式合并为一个方程式,但是您可以按照图片将其重写,那将是同一件事)。
希望在掩盖所有这些之后,对目标函数的动机和相应的松弛变量对您有意义。
如果我正确理解了这个问题,那么您还希望代码计算此目标/损失函数,我认为还不错。我尚未对此进行测试,但是我认为这应该是您想要的。
# Function for calculating the error/loss for a SVM. I assume that:
# - 'x' is 2d array representing the vectors of the data points
# - 'y' is an array representing the values each vector actually gives
# - 'weights' is an array of weights that we tune for the regression
# - 'epsilon' is a scalar representing the breadth of our margin.
def optimization_objective(x, y, weights, epsilon):
# Calculates first term of objective (note that norm^2 = dot product)
margin_term = np.dot(weight, weight) / 2
# Now calculate second term of objective. First get the sum of slacks.
slack_sum = 0
for i in range(len(x)): # For each observation
# First find the absolute distance between expected and observed.
diff = abs(hypothesis(x[i]) - y[i])
# Now subtract epsilon
diff -= epsilon
# If diff is still more than 0, then it is an 'outlier' and will have slack.
slack = max(0, diff)
# Add it to the slack sum
slack_sum += slack
# Now we have the slack_sum, so then multiply by C (I picked this as 1 aribtrarily)
C = 1
slack_term = C * slack_sum
# Now, simply return the sum of the two terms, and we are done.
return margin_term + slack_term
我可以在具有少量数据的计算机上使用此功能,并且例如,如果阵列的结构不同,但是您可能需要对它进行一些更改以使用数据。另外,我不是最精通python的人,因此这可能不是最有效的实现,但是我的目的是使其易于理解。
现在,请注意,这只是计算误差/损失(无论您要调用什么)。要使其实际最小化,需要进行拉格朗日语和严格的二次编程,这是一项艰巨的任务。有可用的库来执行此操作,但是如果您想像这样做一样免费使用此库,则祝您好运,因为这样做不是在公园散步。
最后,我想指出的是,这些信息大部分是从我去年学习的ML课上获得的笔记中获得的,而教授(Abu-Mostafa博士)对我学习这些材料很有帮助。该课程的讲座在线(由同一教授教授),并且与该主题相关的主题是here和here(尽管在我看来,您应该收看所有的演讲,它们还是有很大帮助的)。如果您需要解决任何问题,或者您认为我在某个地方犯了错误,请发表评论/问题。如果您仍然不明白,我可以尝试修改答案以使其更有意义。希望这可以帮助!
关于algorithm - 了解支持向量回归(SVR),我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/52137097/