我有一个具有以下结构的数据框:
date kind sector
0 2017-02-01 P A
1 2017-02-01 P A
2 2017-02-01 L A
3 2017-02-01 G A
4 2017-02-01 P B
5 2017-02-01 P B
6 2017-02-01 L B
7 2017-02-01 T B
8 2017-02-02 P A
9 2017-02-02 P A
10 2017-02-02 L A
11 2017-02-02 T A
12 2017-02-02 A B
13 2017-02-02 P B
14 2017-02-02 L B
15 2017-02-02 L B
我想创建一个具有以下格式的聚合
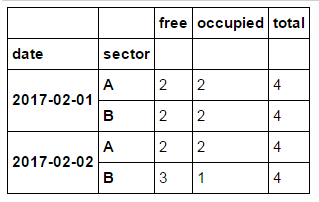
date sector free occupied total
2017-02-01 A 2 2 4
2017-02-01 B 2 2 4
2017-02-02 A 2 2 4
2017-02-02 A 3 1 4
其中的规则是,如果kind == P被占用,则else空闲,总计为所有条目的总和。我尝试在分组上使用 apply 但它不起作用:
df.groupby(['date', 'kind']).apply(lambda x: 1 if x == 'P' else 0)
分割数据帧并合并也不起作用:
df_p = df[df.kind == 'P']
df_np = df[df.kind != 'P']
df_t = df_p.groupby(['date', 'sector'], as_index=False).count()
df_nt = df_np.groupby(['date', 'sector'], as_index=False).count()
df_nt.rename(columns={'kind':'free'}, inplace=True)
df_t = pd.concat([df_t, df_nt])
有办法计算吗?
最佳答案
为“占用”和“空闲”创建两个新变量:
df['occupied'] = (df.kind == "P").astype(int)
df['free'] = (df.kind != "P").astype(int)
然后聚合(此处使用 OrderedDict 而不是 dict 来实现所需的输出列排序):
df_2 = (
df.groupby(["date","sector"])
.agg(OrderedDict((("free" , np.sum) , ("occupied" , np.sum))))
)
并创建总计列:
df_2["total"] = df_2["free"] + df_2["occupied"]
输出:
关于python - pandas 数据帧上的条件过滤器和 groupby,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/43923740/