我有一组已知且有限的二元谓词:A、B、C、...
还有一大堆规则,包含带有 OR、AND、NOT 运算符的谓词。即
R1 = A AND B
R2 = NOT(C) OR B
R3 = ((A OR B) AND C) OR NOT(C)
当获得所有谓词的二元赋值时,我想优化规则的计算。
为此,我可以根据需要修改规则定义,只要逻辑不会改变(相同的谓词分配将在每个规则上给出相同的计算结果)。
我正在考虑创建某种联合决策树,但不知道如何判断什么是优化的安排。
注意:我不关心构建计算算法的复杂度,只关心计算复杂度。
最佳答案
对于少量谓词,您可以提前计算所有结果以创建缓存。请注意,您的缓存中将有 2 ^(谓词数量)条目。
对于大量谓词,您无法执行此操作。我想说这听起来像动态编程,因为规则可能有重叠的组件。为了增加这种重叠,您可以重写所有规则以使用单一类型的操作,例如与非。然后,您可以创建一个图表,其中谓词是输入,规则是输出。
所以你的规则看起来像:
R1 = (A NAND B) NAND (A NAND B)
R2 = (B NAND B) NAND C
R3 = (A NAND A) NAND (B NAND B) NAND C
您已经可以看到一些重叠。这将随着规则数量的增加而增加。您的图表将如下所示:
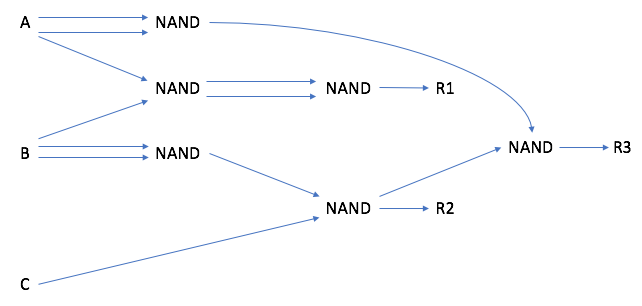
一旦获得二进制分配,您就可以从左到右计算图表。或者在动态编程风格中,您从 R1 开始并缓存所有中间结果以供以后使用,然后对 R2 和 R3 执行相同的操作。
关于algorithm - 优化大量基于二元谓词的规则的计算,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/47649591/