我的任务是创建许多模型,选择预测效果最好的模型并将数据传递给该模型进行预测。示例灵感来自R for data science书本
library(modelr)
library(tidyverse)
library(gapminder)
gapminder
country_model1 <- function(df) {lm(lifeExp ~ year, data = df)}
country_model2 <- function(df) {lm(lifeExp ~ year+gdpPercap, data = df)}
country_model3 <- function(df) {lm(lifeExp ~ year+gdpPercap+pop, data = df)}
by_country <- gapminder %>%
group_by(country, continent) %>%
nest() %>%
mutate(model1 = map(data, country_model1),
model2 = map(data, country_model2),
model3 = map(data, country_model3))
所以我为每个国家/地区准备了 3 个模型。 我可以找到每个模型的r平方,但停在这里:(
r_sq <- by_country %>%
mutate(glance1 = map(model1, broom::glance),
glance2 = map(model2, broom::glance),
glance3 = map(model3, broom::glance)) %>%
unnest(glance1:glance3, .drop = TRUE) %>%
select(country, continent, starts_with('r.sq'))
如何以整洁的方式:
- 选择 3 项中哪一项对每个特定国家/地区的预测效果更好?
- 将新数据传递给所选模型并返回预测?
最佳答案
我们可以为每个国家/地区确定具有最高 r^2 的模型,如下所示:
best_fits <- r_sq %>%
pivot_longer(-c(country, continent), names_to = "r_sq_version") %>%
group_by(country, continent) %>%
slice_max(value) %>%
ungroup()
不足为奇的是,第三个模型(此处称为 r.squared2,源自 r_sq 中的名称)始终提供最高的相关性,因为该模型需要更多输入并且具有更多自由度。
让我们制作一些新数据,采用原始数据,但在日期上添加 100 年。
by_country_new <- gapminder %>%
group_by(country, continent) %>%
mutate(year = year + 100,
gdpPercap = gdpPercap,
pop = pop) %>%
select(-lifeExp) %>% # Presumably we don't know this and are trying to predict using known data
nest()
然后,我们可以将每个国家/地区的最佳模型应用于新数据:(感谢@mrflick https://stackoverflow.com/a/63201855/6851825)
best_fits %>%
left_join(by_country) %>%
left_join(by_country_new, by = c("country", "continent")) %>%
mutate(best_model = case_when(
r_sq_version == "r.squared2" ~ model3,
r_sq_version == "r.squared1" ~ model2,
r_sq_version == "r.squared" ~ model1,
)) %>%
select(-c(model1:model3)) %>%
mutate(prediction = map2(best_model, data.y,
~broom::augment(.x, newdata = .y))) -> new_fits
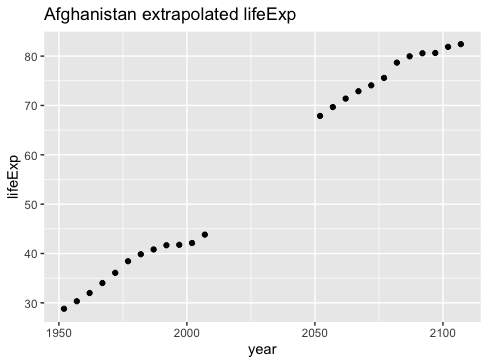
然后我们可以看到这些预测看起来如何像原始数据中建立的时间趋势的延续(由于新数据中人口和 GDP 的变化而导致一些其他变化)。
new_predictions <- new_fits %>%
filter(country == "Afghanistan") %>%
select(prediction) %>%
unnest_wider(prediction) %>%
flatten_dfr() %>%
rename(lifeExp = ".fitted")
gapminder %>%
filter(country == "Afghanistan") %>%
bind_rows(new_predictions) %>%
ggplot(aes(year, lifeExp)) +
geom_point() +
labs(title = "Afghanistan extrapolated lifeExp")
关于r - 多个型号: how to select best model and make prediction,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/66399901/