我有一个数据框如下;
df_d = {'consolidate_elem': {0: np.nan,
1: np.nan,
2: np.nan,
3: np.nan,
4: np.nan,
5: np.nan,
6: np.nan,
7: np.nan,
8: np.nan,
9: np.nan,
10: np.nan},
'A': {0: np.nan,
1: np.nan,
2: '6/9/1972',
3: '9/4/1943',
4: '1/29/1944',
5: '7/31/1965',
6: '4/5/1979',
7: np.nan,
8: '3/17/2000',
9: '3/18/2000',
10: '3/17/2000'},
'B': {0: np.nan,
1: np.nan,
2: np.nan,
3: 'Yes',
4: np.nan,
5: np.nan,
6: np.nan,
7: np.nan,
8: np.nan,
9: np.nan,
10: np.nan},
'C': {0: np.nan,
1: np.nan,
2: np.nan,
3: np.nan,
4: 'Yes',
5: 'Yes',
6: np.nan,
7: 'Yes',
8: 'Yes',
9: 'Yes',
10: 'Yes'},
'D': {0: '11100',
1: '11721',
2: np.nan,
3: '55626',
4: '5,562,655,626.00',
5: np.nan,
6: np.nan,
7: '33050',
8: '33050',
9: '33050',
10: np.nan}}
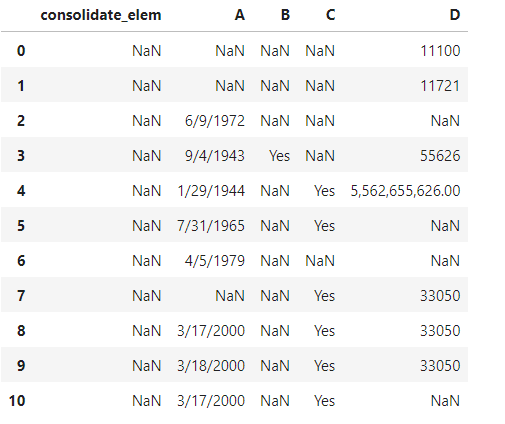
在这里,我想用列名填充列consolidate_elem,其行在上面的数据框中不是NAN。预期输出如下;
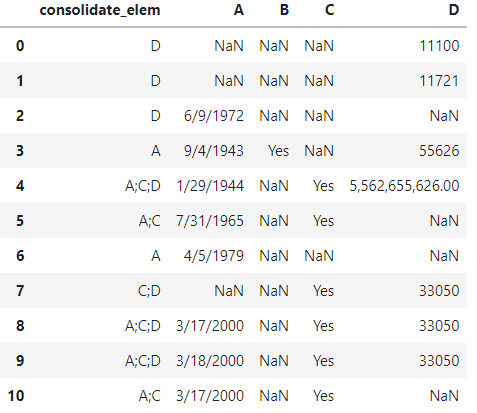
因此,在第一行中,我们在 D 列中有一个值,因此在 consolidate_elem 中将其填充为 D。
类似地,在索引 -4 中,它与 A;C;D 一样,因为它们具有值。
最佳答案
使用DataFrame.dot用于通过比较非缺失值创建的掩码进行矩阵乘法 DataFrame.notna省略第一列:
df = pd.DataFrame(df_d)
df['consolidate_elem'] = df.iloc[:, 1:].notna().dot(df.columns[1:] + ';').str.strip(';')
print (df)
consolidate_elem A B C D
0 D NaN NaN NaN 11100
1 D NaN NaN NaN 11721
2 A 6/9/1972 NaN NaN NaN
3 A;B;D 9/4/1943 Yes NaN 55626
4 A;C;D 1/29/1944 NaN Yes 5,562,655,626.00
5 A;C 7/31/1965 NaN Yes NaN
6 A 4/5/1979 NaN NaN NaN
7 C;D NaN NaN Yes 33050
8 A;C;D 3/17/2000 NaN Yes 33050
9 A;C;D 3/18/2000 NaN Yes 33050
10 A;C 3/17/2000 NaN Yes NaN
或者按名称删除列:
df['consolidate_elem'] = (df.drop('consolidate_elem', axis=1).notna()
.dot(df.columns.drop('consolidate_elem') + ';')
.str.strip(';'))
关于python - 如何在 Pandas 中填充行不为 NULL 的列名?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/71423043/