我有一个稍微进入饱和状态的外部校准曲线。所以我拟合了一个二阶多项式和一个测量样本的数据框,我想知道其中的浓度。
df_calibration=structure(list(dilution = c(0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7,
0.8, 0.9, 1, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1),
area = c(1000, 2000, 3000, 4000, 5000, 6000, 7000, 7800,
8200, 8500, 1200, 2200, 3200, 4200, 5200, 6200, 7200, 8000,
8400, 8700), substance = c("A", "A", "A", "A", "A", "A",
"A", "A", "A", "A", "b", "b", "b", "b", "b", "b", "b", "b",
"b", "b")), row.names = c(NA, 20L), class = "data.frame")
df_samples=structure(list(area = c(1100, 1800, 2500, 3200, 3900, 1300, 2000,
2700, 3400, 4100), substance = c("A", "A", "A", "A", "A", "b",
"b", "b", "b", "b")), row.names = c(NA, 10L), class = "data.frame")
现在为了计算测量 sample 的实际稀释度,我采用了由此拟合生成的参数:
df_fits=df_calibration %>% group_by(substance) %>%
do(fit = lm(area ~ poly(dilution,2), data = .))%>%
tidy(fit) %>%
select(substance, term, estimate) %>%
spread(term, estimate)
df_fits=df_fits %>% rename(a=`poly(dilution, 2)2`,b=`poly(dilution, 2)1`,c=`(Intercept)`)
#join parameters with sample data
df_samples=left_join(df_samples,df_fits)
而这个公式

#calculate with general solution for polynomial 2nd order
df_samples$dilution_calc=
(df_samples$b*(-1)+sqrt(df_samples$b^2-(4*df_samples$a*(df_samples$c-df_samples$area))))/(2*df_samples$a)
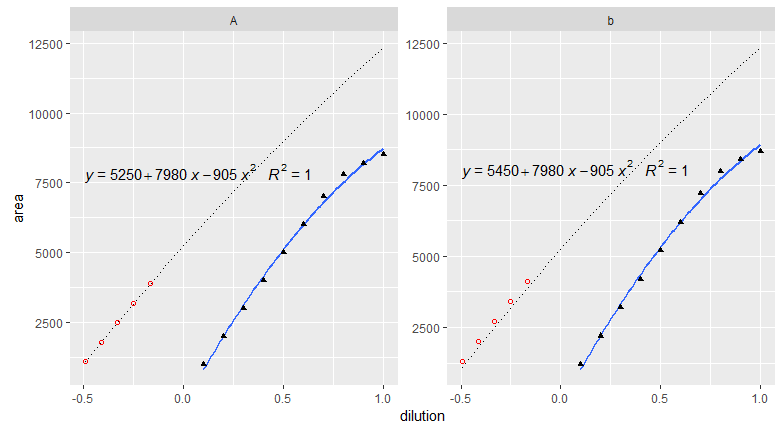
但是,当我现在绘制此图时,我注意到一些非常奇怪的事情。
计算出的 x 值(稀释)没有出现在来自
stat_smooth() 的曲线上.附加的虚线与物质“A”的图形中方程的参数(与数据框中的数字匹配)一起放置。所以我的计算应该是正确的(或不正确?)为什么会有差异?我究竟做错了什么?我如何从 stat_smooth() 完成的拟合中获取参数?my.formula=y ~ poly(x,2)
ggplot(df_calibration, aes(x = dilution, y = area)) +
stat_smooth(method = "lm", se=FALSE, formula = my.formula) +
stat_function(fun=function(x){5250+(7980*x)+(-905*x^2)},
inherit.aes = F,linetype="dotted")+
stat_poly_eq(formula = my.formula,
aes(label = paste(..eq.label.., ..rr.label.., sep = "~~~")),
parse = TRUE) +
geom_point(shape=17)+
geom_point(data=df_samples,
aes(x=dilution_calc,y=area),
shape=1,color="red")+
facet_wrap(~substance,scales = "free")
任何建议将不胜感激:-)
最佳答案
默认情况下,poly计算正交多项式。您可以使用 raw=TRUE 关闭正交化。争论。
请注意,该公式有两次出现:一次在拟合回归时使用原始变量名称,然后在 stat_smooth 中使用。使用通用变量名 x和 y .但否则它应该是相同的公式,与raw=TRUE .
library("tidyverse")
# Define/import your data here....
df_fits <- df_calibration %>%
group_by(substance) %>%
do(fit = lm(area ~ poly(dilution, 2, raw = TRUE), data = .)) %>%
broom::tidy(fit) %>%
select(substance, term, estimate) %>%
spread(term, estimate) %>%
# It is simpler to rename the coefficients here
setNames(c("substance", "c", "b", "a"))
# join parameters with sample data
df_samples <- left_join(df_samples, df_fits)
# calculate with general solution for polynomial 2nd order
df_samples <- df_samples %>%
mutate(dilution_calc = (b * (-1) + sqrt(b^2 - (4 * a * (c - area)))) / (2 * a))
my.formula <- y ~ poly(x, 2, raw = TRUE)
df_calibration %>%
ggplot(aes(x = dilution, y = area)) +
stat_smooth(method = "lm", se = FALSE, formula = my.formula) +
geom_point(shape = 17) +
geom_point(
data = df_samples,
aes(x = dilution_calc, y = area),
shape = 1, color = "red"
) +
facet_wrap(~substance, scales = "free")

创建于 2019-03-31 由 reprex package (v0.2.1)
关于r - 为什么 do(lm...) 和 geom_smooth(method ="lm") 之间有区别?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/55437248/