我目前正在处理 Robert Sedgewick's Algorithms book .在书中,我试图了解 select 的实现二叉搜索树中的方法。作者使用一个BST来实现一个符号表。作者介绍了select方法如下:
Suppose that we seek the key of rank k (the key such that precisely k other keys in the BST are smaller). If the number of keys t in the left sub- tree is larger than k, we look (recursively) for the key of rank k in the left subtree; if t is equal to k, we return the key at the root; and if t is smaller than k, we look (recursively) for the key of rank k - t - 1 in the right subtree. As usual, this de- scription serves both as the basis for the recursive select() method on the facing page and for a proof by induction that it works as expected.
我想具体了解
k - t - 1的目的是什么当左节点的大小小于小于 k 的键数时传递给递归选择方法. public Key select(int k)
{
return select(root, k).key;
}
private Node select(Node x, int k)
{ // Return Node containing key of rank k.
if (x == null) return null;
int t = size(x.left);
if (t > k) return select(x.left, k);
else if (t < k) return select(x.right, k-t-1);
else return x;
}
select 的上述实现二叉搜索树的方法。当条件t < k作者通过k-t-1到递归 select方法调用,但我仍然无法弄清楚为什么会这样。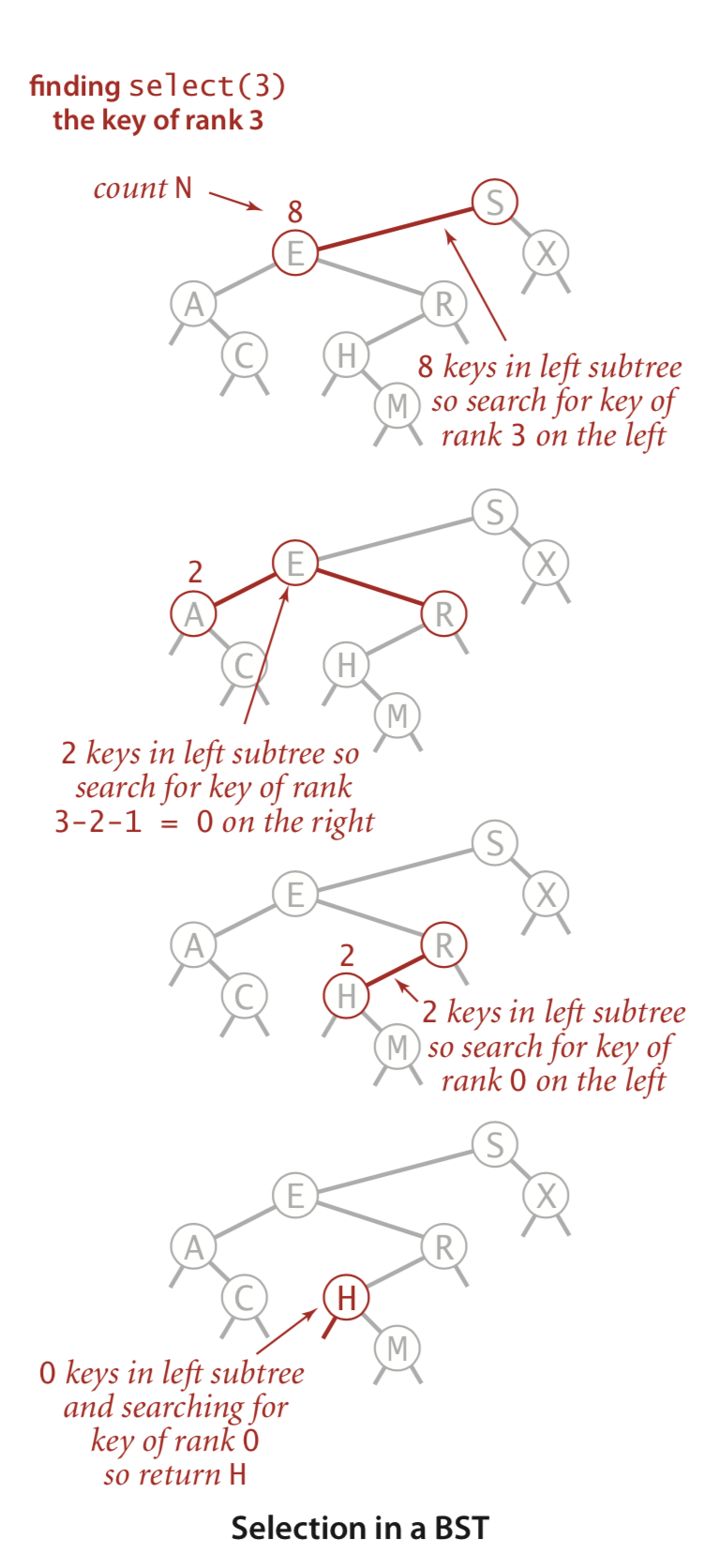
最佳答案
k − t − 1 等于 k − (t + 1)。当 t < k 并且我们递归到右子树时,左子树中的 t 个元素和 1 根元素都计入右子树中元素的排名,因此我们需要调整 k 以匹配。
关于java - 二叉搜索树选择方法实现,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/64969887/