当我在 上训练我的 pytorch 模型时GPU 设备,我的 python 脚本突然被杀死了。潜入操作系统日志文件,我发现脚本被 OOM 杀手杀死,因为我的 CPU 内存不足。很奇怪我在上训练我的模型GPU 设备,但我用完了 CPU 内存。
Snapshot of OOM killer log file

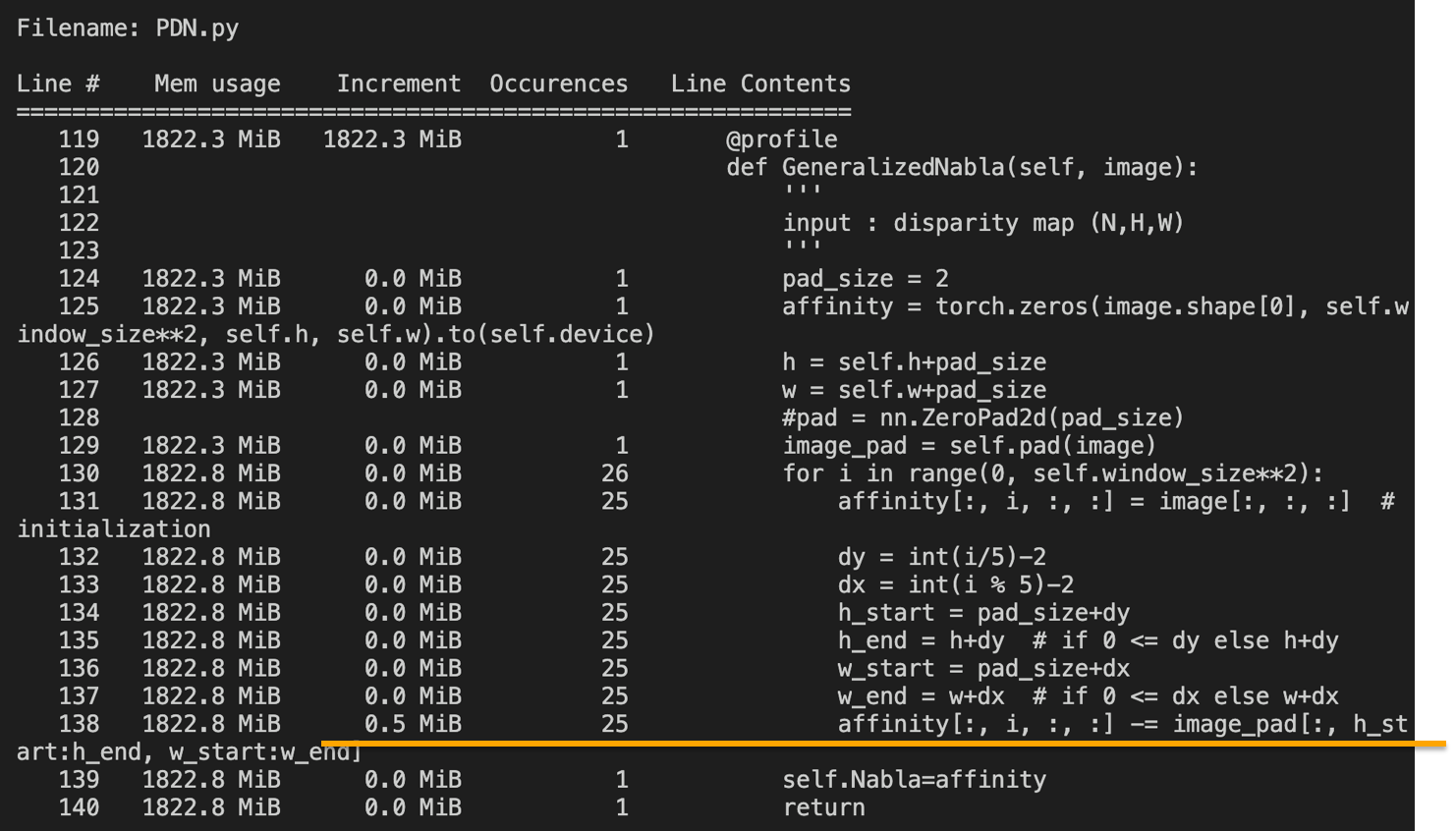
为了调试这个问题,我安装了python memory profiler。从内存分析器查看日志文件,我发现当列明智 -= 操作发生后,我的 CPU 内存逐渐增加,直到 OOM 杀手杀死了我
程序。
Snapshot of Python memory profiler

很奇怪,我尝试了很多方法来解决这个问题。最后,我发现在赋值操作之前,我先分离Tensor。令人惊讶的是,它解决了这个问题。但我不明白它为什么起作用。这是我的原始函数代码.
{kind=link}
{kind=link}
def GeneralizedNabla(self, image):
pad_size = 2
affinity = torch.zeros(image.shape[0], self.window_size**2, self.h, self.w).to(self.device)
h = self.h+pad_size
w = self.w+pad_size
#pad = nn.ZeroPad2d(pad_size)
image_pad = self.pad(image)
for i in range(0, self.window_size**2):
affinity[:, i, :, :] = image[:, :, :].detach() # initialization
dy = int(i/5)-2
dx = int(i % 5)-2
h_start = pad_size+dy
h_end = h+dy # if 0 <= dy else h+dy
w_start = pad_size+dx
w_end = w+dx # if 0 <= dx else w+dx
affinity[:, i, :, :] -= image_pad[:, h_start:h_end, w_start:w_end].detach()
self.Nabla=affinity
return
最佳答案
以前当您没有使用 .detach()在你的张量上,你也在积累计算图,随着你继续,你不断积累越来越多,直到你最终耗尽你的内存到它崩溃的地步。
当你做 detach() ,您可以有效地获取数据,而无需计算梯度所需的先前纠缠的历史。
关于python - Pytorch 模型训练 CPU 内存泄漏问题,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/65107933/