我在每行输入中都有一条记录,每条记录大约有 10 个字段。首先,我按三个字段 (field1, field2, field3) 对记录进行分组,因此一个 mapper/reducer 负责一个唯一的组(基于三个字段)。在每个组中,我根据另一个整数字段 timestamp 对记录进行排序,并通过添加另一个字段用相同的标签 aTag 标记组中的每个记录。
假设在 mapper#1 中,我将一个排序组标记为 aTag,在 mapper#2 中,我标记了另一个组(一个不同的组,因为我最初根据三个字段对记录进行了分组) 具有相同的标签 aTag。
现在,如果我根据标签字段对记录进行分组(即,在不同的映射器中对组进行分组),我注意到每个组内的顺序不再保留。我期待的是,由于每个映射器都有一个组,其中所有记录都具有相同的标签,因此按标签名称分组应该只涉及从其他映射器获取相关组并连接它们而无需重新排序每个单独的组。
是不是因为我试图以 gzip 格式存储记录,因此它会尝试重新排序记录以实现更好的压缩?另外我想知道如何在按标签名称分组后保留顺序。
最佳答案
看起来您正在尝试在本地内存中自己实现 MapReduce 的排序步骤,但是它完全忽略了您所做的并重新排序每个组中的项目。解决这个问题的正确方法是在键上指定一个比较器,以便在每个分区内,合并到 reducer 的输入是根据该比较函数。这意味着
- 您不必自己进行分类
- 您不会在一台机器上尝试对非常大的组进行排序时耗尽内存。
在您的案例中,您似乎想要将 timestamp 添加到键集中,告诉它根据前三个键进行分区,并告诉它根据时间戳进行排序。
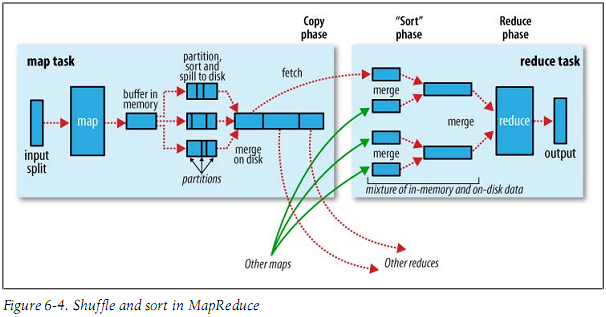
有关详细信息,请参见下图和 Where is Sort used in MapReduce phase and why?
关于Hadoop 映射减少 : Order of records while grouping,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/15144578/