我是 Hive 的新手,遇到了一些问题。我试图在此处和其他网站上找到答案,但没有成功……我还尝试了许多不同的查询,但都没有成功。
我有 my source table我想创建 new table like this .
是:
{kind=link}
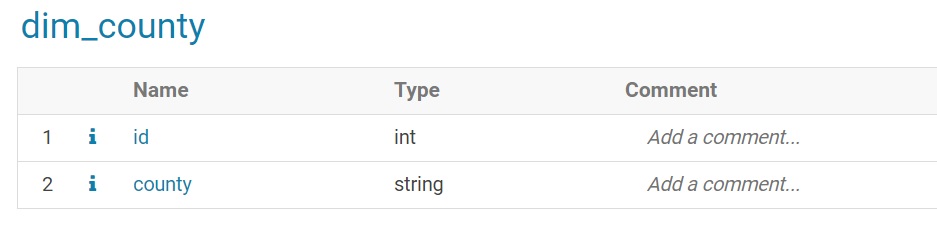{kind=link}
最佳答案
你可以遵循这种方法。
A CTAS(按选择创建表)
以你的例子,这个 CTAS 可以工作
CREATE TABLE t_county
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE AS
WITH t AS(
SELECT DISTINCT county, ROW_NUMBER() OVER() AS id
FROM counties)
SELECT id, county
FROM t;
你不能在 Hive 上有主键或外键,因为你在像 Oracle 或 MySql 这样的 RBDMS 上有主键,因为 Hive 是读模式而不是像 Oracle 那样写模式,所以你不能在 Hive 上实现任何类型的约束。
关于hadoop - 如何使用另一个表中的特定列值在 Hive 中创建表,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/61842796/