我对统计和 R 很陌生。也许这是一个非常微不足道的问题,但我真的不明白这是如何工作的。
假设我使用 dnorm(5, 0, 2.5) .这意味着什么?
我看到一些资源,他们说这个函数计算密度曲线中点的高度。
现在我又读到一个数字在连续分布中的确切概率为 0。所以,我的问题是,如果我能找出某个值的高度或概率,那么它为什么是 0?
我知道我混淆了一些概念。但是我找不到我错在哪里。如果您能抽出时间让我理解这一点,那就太好了。提前致谢。
最佳答案
密度返回一个本身不会直接转换为概率的数字。但它给出了一条曲线的高度,如果在所有可能的数字范围内绘制,则其下方的面积加起来为 1。
考虑一下。如果我制作矢量 x从 -7.5 到 7.5,相隔 0.1 的均匀间隔数字的密度,并为 x 的每个值获得均值为 0 和标准差为 2.5 的正态变量的密度.
x <- seq(from = -7.5, to = 7.55, by = 0.1)
y <- dnorm(x, 0, 2.5)
由这些密度(我存储为
y )形成的曲线下面积的近似值乘以它们之间的距离 (0.1) 接近 1:> sum(y * 0.1)
[1] 0.9974739
如果你用微积分正确地做到了这一点,而不是用数字来近似它,它就会是一个。
为什么这很有用?曲线部分下的累积面积可用于估计变量出现在特定范围内的任何位置的概率,尽管正如您的一位消息来源指出的那样,对于连续变量,任何精确数字的机会在技术上为零。
考虑这个图形。阴影空间的面积显示了正态分布中的变量(均值为零,标准差 2.5)介于 -7.5 和 4 之间的可能性。这导致了许多有用的应用。
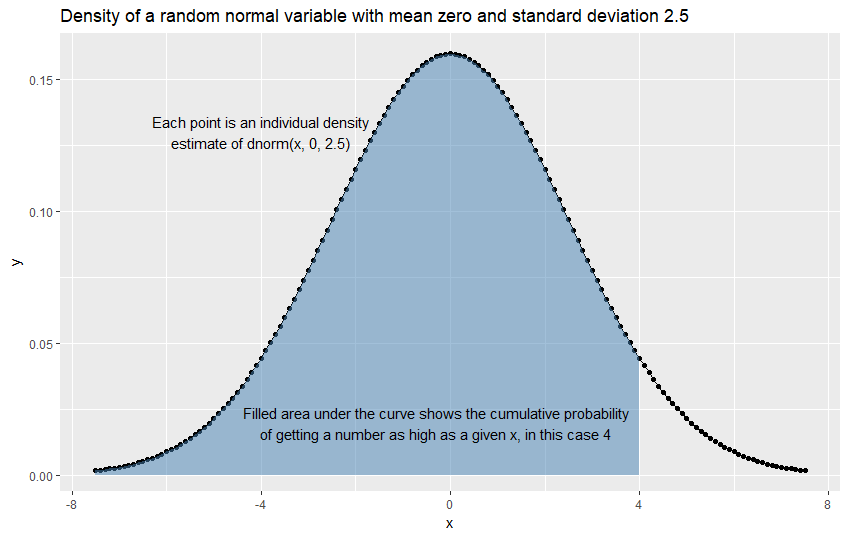
用:
library(ggplot2)
d <- data.frame(x, y)
ggplot(d, aes(x = x, y = y)) +
geom_line() +
geom_point() +
geom_ribbon(fill = "steelblue", aes(ymax = y), ymin = 0, alpha = 0.5, data = subset(d, x <= 4)) +
annotate("text", x= -4, y = 0.13, label = "Each point is an individual density\nestimate of dnorm(x, 0, 2.5)") +
annotate("text", x = -.3, y = 0.02, label = "Filled area under the curve shows the cumulative probability\nof getting a number as high as a given x, in this case 4") +
ggtitle("Density of a random normal variable with mean zero and standard deviation 2.5")
关于r - dnorm 是如何工作的?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/48483064/