所以,我试图用以下类型的幂律拟合一组数据:
def f(x,N,a): # Power law fit
if a >0:
return N*x**(-a)
else:
return 10.**300
par,cov = scipy.optimize.curve_fit(f,data,time,array([10**(-7),1.2]))
else 条件只是强制 a 为正数。使用 scipy.optimize.curve_fit 产生 an awful fit (green line) ,分别为 N 和 a 返回 1.2e+04 和 1.9e0-7 的值,与数据绝对没有交集。从我手动输入的拟合来看,N 和 a 的值应该分别落在 1e-07 和 1.2 左右,尽管将它们作为初始参数放入 curve_fit 不会改变结果。删除 a 为正的条件会导致更差的拟合,因为它选择了负数,这会导致具有错误符号斜率的拟合。
{kind=link}
我不知道如何让一个可信的,更不用说可靠的,适合这个例程,但我找不到任何其他好的 Python 曲线拟合例程。我需要编写自己的最小二乘算法还是我在这里做错了什么?
最佳答案
更新
在原帖中,我展示了一个使用 lmfit 的解决方案。这允许为您的参数分配界限。从 0.17 版本开始,scipy 还允许直接为您的参数分配边界(请参阅 documentation )。请在以下 之后找到此解决方案编辑 希望可以作为如何使用 scipy 的最小示例 curve_fit带参数边界。
原帖
正如@Warren Weckesser 所建议的,您可以使用 lmfit完成此任务,这允许您为参数分配界限并避免这个“丑陋”的 if 子句。
由于您没有提供任何数据,因此我创建了一些数据,如下所示:
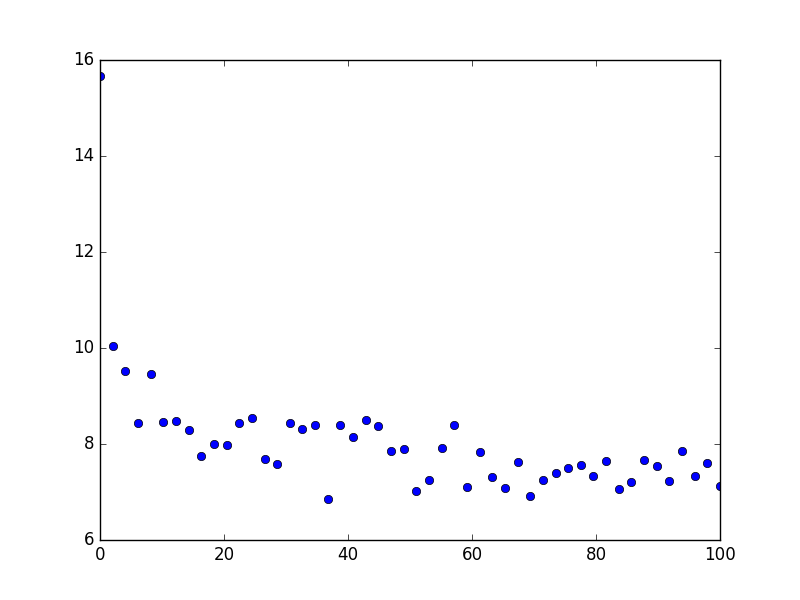
他们守法f(x) = 10.5 * x ** (-0.08)
我适合它们 - 正如@roadrunner66 所建议的 - 通过将幂律转换为线性函数:
y = N * x ** a
ln(y) = ln(N * x ** a)
ln(y) = a * ln(x) + ln(N)
所以我第一次使用
np.log在原始数据上,然后进行拟合。当我现在使用 lmfit 时,我得到以下输出:[[Variables]]
lN: 2.35450302 +/- 0.019531 (0.83%) (init= 1.704748)
a: -0.08035342 +/- 0.005158 (6.42%) (init=-0.5)
所以
a非常接近原始值和np.exp(2.35450302)给出 10.53 这也非常接近原始值。情节如下所示;如您所见,拟合很好地描述了数据:

这是带有几个内联注释的完整代码:
import numpy as np
import matplotlib.pyplot as plt
from lmfit import minimize, Parameters, Parameter, report_fit
# generate some data with noise
xData = np.linspace(0.01, 100., 50.)
aOrg = 0.08
Norg = 10.5
yData = Norg * xData ** (-aOrg) + np.random.normal(0, 0.5, len(xData))
plt.plot(xData, yData, 'bo')
plt.show()
# transform data so that we can use a linear fit
lx = np.log(xData)
ly = np.log(yData)
plt.plot(lx, ly, 'bo')
plt.show()
def decay(params, x, data):
lN = params['lN'].value
a = params['a'].value
# our linear model
model = a * x + lN
return model - data # that's what you want to minimize
# create a set of Parameters
params = Parameters()
params.add('lN', value=np.log(5.5), min=0.01, max=100) # value is the initial value
params.add('a', value=-0.5, min=-1, max=-0.001) # min, max define parameter bounds
# do fit, here with leastsq model
result = minimize(decay, params, args=(lx, ly))
# write error report
report_fit(params)
# plot data
xnew = np.linspace(0., 100., 5000.)
# plot the data
plt.plot(xData, yData, 'bo')
plt.plot(xnew, np.exp(result.values['lN']) * xnew ** (result.values['a']), 'r')
plt.show()
编辑
假设您安装了 scipy 0.17,您还可以使用
curve_fit 执行以下操作.我将它用于您对幂律的原始定义(下图中的红线)以及对数数据(下图中的黑线)。数据的生成方式与上述相同。情节如下:
如您所见,数据描述得非常好。如果您打印
popt和 popt_log ,您获得 array([ 10.47463426, 0.07914812])和 array([ 2.35158653, -0.08045776]) , 分别(注意:对于字母,您必须取第一个参数的指数 - np.exp(popt_log[0]) = 10.502 接近原始数据)。这是整个代码:
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
# generate some data with noise
xData = np.linspace(0.01, 100., 50)
aOrg = 0.08
Norg = 10.5
yData = Norg * xData ** (-aOrg) + np.random.normal(0, 0.5, len(xData))
# get logarithmic data
lx = np.log(xData)
ly = np.log(yData)
def f(x, N, a):
return N * x ** (-a)
def f_log(x, lN, a):
return a * x + lN
# optimize using the appropriate bounds
popt, pcov = curve_fit(f, xData, yData, bounds=(0, [30., 20.]))
popt_log, pcov_log = curve_fit(f_log, lx, ly, bounds=([0, -10], [30., 20.]))
xnew = np.linspace(0.01, 100., 5000)
# plot the data
plt.plot(xData, yData, 'bo')
plt.plot(xnew, f(xnew, *popt), 'r')
plt.plot(xnew, f(xnew, np.exp(popt_log[0]), -popt_log[1]), 'k')
plt.show()
关于python - SciPy 曲线拟合失败幂律,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/35903506/