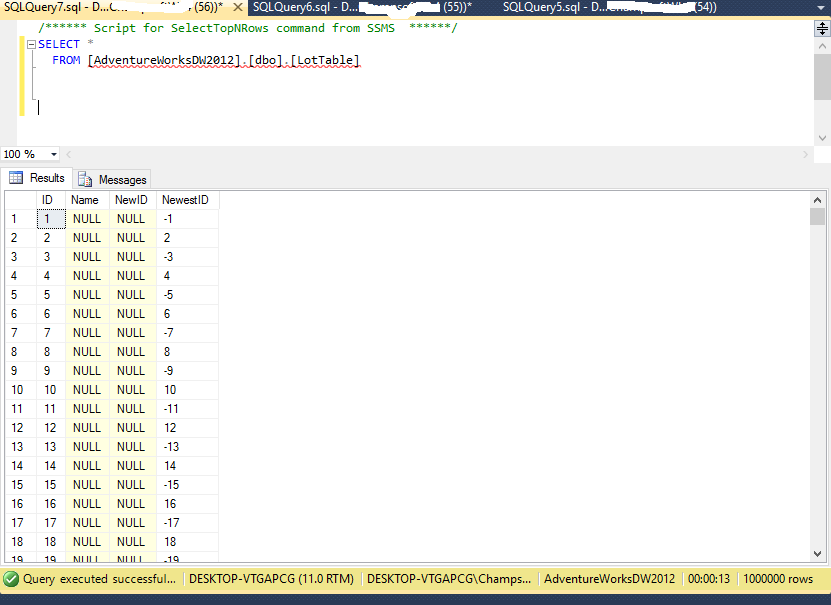
我有一个包含 100 万条记录的 SQL 表。当我打电话时
SELECT *
FROM [AdventureWorksDW2012].[dbo].[LotTable]
完成查询花了 13 秒。
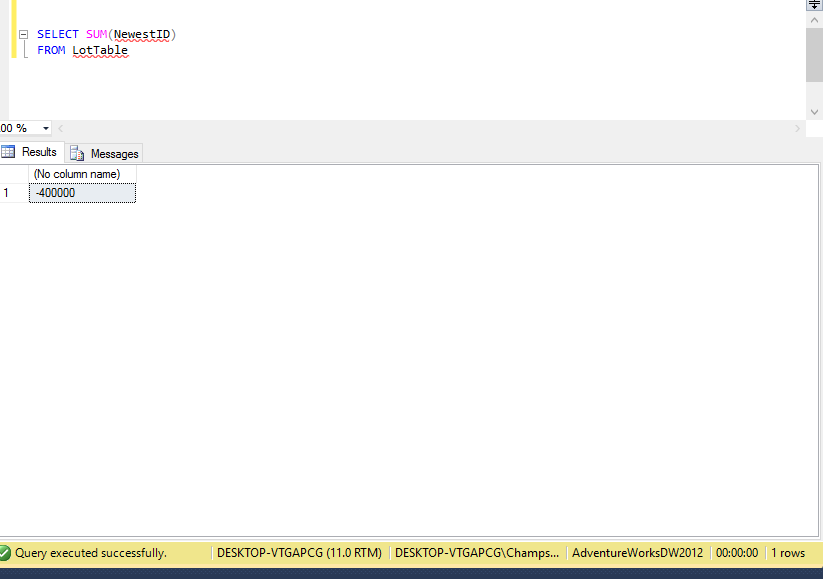
我运行以下查询来获取 ID 列的 SUM()。它包含包含正值和负值的随机数。
SELECT SUM(NewestID)
FROM LotTable
这个查询只花了 500 毫秒。要执行 SUM(),SQL 引擎应该读取这些值并对其应用一些操作。但它的运行速度怎么比 SELECT() 还要快。背后的逻辑是什么?请参阅下面的图片。提前致谢。
最佳答案
这是预期的行为。您会看到,当您向数据库系统发送查询时,会发生以下几件事:
- 分析、优化查询并设计执行模式,
- 查询已执行(!),
- 结果被传达给客户端(!)
最后两项(带感叹号)是加速的潜在来源。
首先,如果您对值进行求和,则不需要存储所有这些值。事实上,您使用了累加器。所以成熟的数据库系统会初始化一个累加器,值为0然后对于它找到的每一行(匹配可选约束),它将将该值添加到累加器中。关键是,累加器使用固定数量的内存。例如,对于整数,通常小于 10 个字节。因此累加器存储在(快速)内存中。
SUM(..)的优势也是它是关联的:((a+b)+c)+d等于(a+b)+(c+d) 。根据数据库的工作和配置方式,它可以将任务分配给多个工作人员,每个工作人员计算表的一部分的总和。然后将这些子和加在一起。
另一方面,如果您执行 SELECT查询,然后将结果逐行写入。因此,存在线性内存使用:对于匹配的每一行,我们都需要内存。对于大型表,旧行可能会被“交换”出 CPU 缓存,有时甚至是内存。因此执行查询需要更长的时间。
最后系统需要响应。现在,如果您执行 SUM(..) ,只有一行。因此传输的数据量很小。一个SELECT查询通常会传输数百行。当然,传输大量数据比传输少量数据需要更多时间。
关于sql-server - SUM() 比 SQL 中的 SELECT() 花费的时间更少。怎么运行的?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/44021032/