我目前正在使用包含风数据的 BUFR 文件。当我在 python 上读取这个文件时,我得到 4 个大向量,纬度向量、经度向量、wind_direction 向量和 Wind_speed 向量。
两个风向量都是经过屏蔽的 Python 数组,因为存在无效数据。发生这种情况是因为数据来自非对地静止卫星。事实上,我成功地从此 BUFR 文件生成了以下图像,以向您展示数据所采用的一般形状。
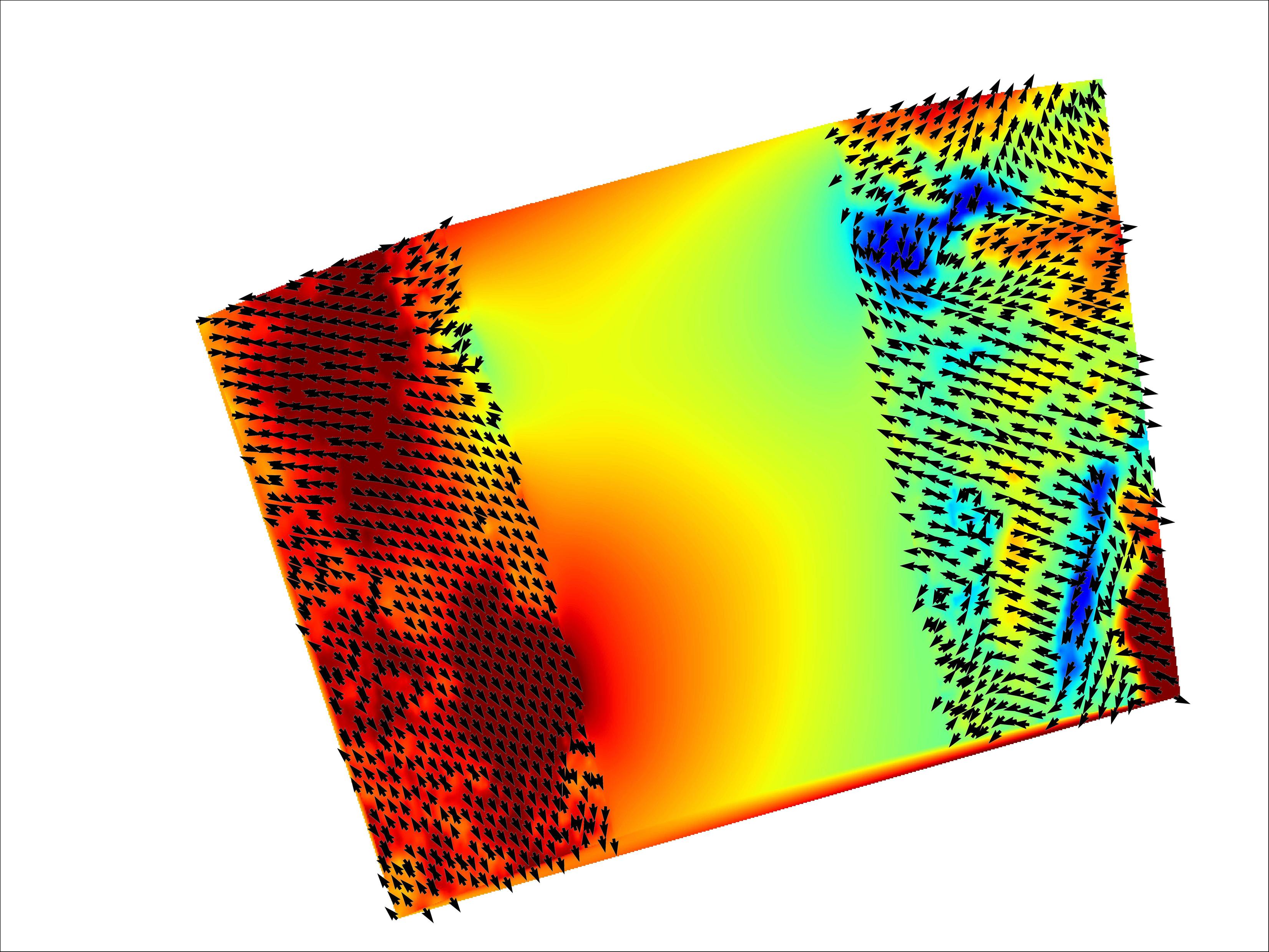
在这张图片中,我绘制了一个色域来表示风速,而箭头显然表示风向。
请注意实际数据的两个波段。不幸的是,我绘制数据的方式在实际数据带之间生成了第三个带(其中色域平滑)。这是函数pcolormesh 的产物。如果我可以叠加两个“pcolormesh 图”,每个图代表一个波段,那么这个问题就会消失。
不幸的是,我不知道如何分离数据“区域”。我考虑过聚类技术,但不知道如何使用另一个数组(风数据)作为聚类规则沿着 latlon 数据进行聚类。
这是我当前的代码:
#!/usr/bin/python
import bufr
import numpy as np
import sys
import matplotlib
matplotlib.use('Agg')
from matplotlib import pyplot as plt
from matplotlib import mlab
WIND_DIR_INDEX = 97
WIND_SPEED_INDEX = 96
bfrfile = sys.argv[1]
print bfrfile
bfr = bufr.BUFRFile(bfrfile)
lon = []
lat = []
wind_d = []
wind_s = []
for record in bfr:
for entry in record:
if entry.index == WIND_DIR_INDEX:
wind_d.append(entry.data)
if entry.index == WIND_SPEED_INDEX:
wind_s.append(entry.data)
if entry.name.find("LONGITUDE") == 0:
lon.append(entry.data)
if entry.name.find("LATITUDE") == 0:
lat.append(entry.data)
lons = np.concatenate(lon)
lats = np.concatenate(lat)
winds_d = np.concatenate(wind_d)
winds_s = np.concatenate(wind_s)
winds_d = np.ma.masked_greater(winds_d,1.0e+6)
winds_s = np.ma.masked_greater(winds_s,1.0e+6)
windu = np.cos((winds_d-180)*(np.pi/180))
windv = np.sin((winds_d-180)*(np.pi/180))
# Data interpolation for pcolormesh (needs gridded data)
xi = np.linspace(lons.min(),lons.max(),lons.size/10)
yi = np.linspace(lats.min(),lats.max(),lats.size/10)
Z = mlab.griddata(lons,lats,winds_s,xi,yi)
X,Y = np.meshgrid(xi,yi)
mydpi = 96
fig = plt.figure(frameon=True)
fig.set_size_inches(1600/mydpi,1200/mydpi)
ax = plt.Axes(fig,[0,0,1,1])
#ax.set_axis_off()
fig.add_axes(ax)
plt.hold(True);
plt.quiver(lons[::5],lats[::5],windu[::5],windv[::5],linewidths=0)
for method in (ax.set_xticks,ax.set_xticklabels,ax.set_yticks,ax.set_yticklabels):
method([])
fig.savefig('/home/cendas/bin/python/bufr_ascat.png',bbox_inches=0,dpi=5*mydpi)
mydpi = 96
fig = plt.figure(frameon=True)
fig.set_size_inches(1600/mydpi,1200/mydpi)
ax = plt.Axes(fig,[0,0,1,1])
#ax.set_axis_off()
fig.add_axes(ax)
plt.hold(True);
try:
plt.pcolormesh(X,Y,Z,alpha=None)
plt.clim(0,10)
except ValueError:
pass
print "Warning: Empty data array."
for method in (ax.set_xticks,ax.set_xticklabels,ax.set_yticks,ax.set_yticklabels):
method([])
fig.savefig('/home/cendas/bin/python/bufr_ascat_color.png',bbox_inches=0,dpi=5*mydpi)
然后,我通常按照此 python 代码使用以下终端命令来组合图像:
convert bufr_ascat.png -transparent white bufr_ascat.png
convert bufr_ascat_color.png -transparent white bufr_ascat_color.png
composite bufr_ascat.png bufr_ascat_color.png bufrascat.png
最佳答案
不要为此滥用集群。
您需要的是简单的选择/过滤;不是结构发现过程。
选择屏蔽数据的平均值。该均值左侧的所有非屏蔽数据是左侧部分,右侧的所有非屏蔽数据是另一个部分?
集群是执行此任务的错误工具。
关于python - 如何在python上分离latlon数据的两个区域,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/24148006/