我正在尝试用 Python 实现和可视化 K 均值算法代码。我有一个使用 make_blobs 创建的数据集,然后使用 K-means 拟合数据并使用 matplotlib.pyplot.scatter 可视化结果。
这是我的代码:
导入和数据创建步骤
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
n_samples = 3000
random_state = 1182
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
# X.shape = (3000, 2)
# y.shape = (3000,) -> y's values range from 0 to 2.
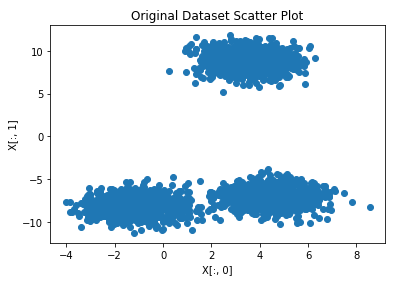
原始数据散点图
plt.scatter(X[:, 0], X[:, 1])
plt.title("Original Dataset Scatter Plot")
plt.xlabel("X[:, 0]")
plt.ylabel("X[:, 1]")
plt.show()
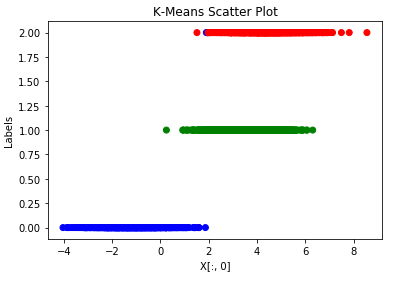
K-Means 训练和可视化
kmeans_model = KMeans(n_clusters=3, random_state=1)
kmeans_model.fit(X)
colors = { 0: 'r',
1: 'b',
2: 'g'}
label_color = [colors[l] for l in y]
plt.scatter(X[:, 0], kmeans_model.labels_, c=label_color)
plt.title("K-Means Scatter Plot")
plt.xlabel("X[:, 0]")
plt.ylabel("Labels")
plt.show()
我的问题是:当我将 plt.scatter 与 X[:, 1] 而不是 X[:, 0],正如我在给定代码中所做的那样,我得到了不同的图,尽管具有相同的集群:
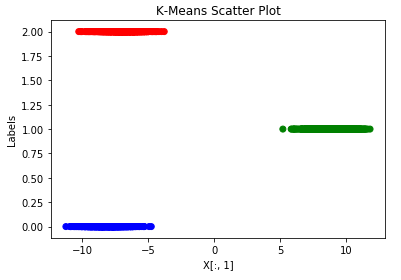
这仍然被认为是 K 均值和散点图的正确实现和使用吗?如果是这样,是否有特殊原因应该选择某些 x 值而不是其他值?
最佳答案
这是一种非常奇怪的可视化聚类方式。如果您想查看模型的表现如何,只需像在第一个图表中那样绘制所有 Blob ,然后提供着色序列label_color。
plt.scatter(X[:,0], X[:,1], c=label_color)

您使用 X[:,0] 或 X[:,1] 的问题设置不正确。这两个维度都代表数据,并且您的图表在某种程度上是正确的,但它们无法解释。
关于python - 如何确定 K 均值和散点图使用哪个 `x` 参数?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/53804309/