让我们想象一个 3x4 的空 NumPy 数组,其中包含左上角的坐标以及水平和垂直方向的步长。 现在我想知道整个数组每个单元格中间的坐标。像这样:
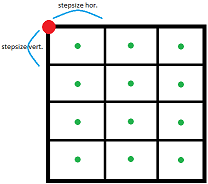
为此,我实现了一个嵌套的 for 循环。
In [12]:
import numpy as np
# extent(topleft_x, stepsize_x, 0, topleft_y, 0, stepsize_y (negative since it's top-left)
extent = (5530000.0, 5000.0, 0.0, 807000.0, 0.0, -5000.0)
array = np.zeros([3,4],object)
cols = array.shape[0]
rows = array.shape[1]
# function to apply to each cell
def f(x,y):
return x*extent[1]+extent[0]+extent[1]/2, y*extent[5]+extent[3]+extent[5]/2
# nested for-loop
def nestloop(cols,rows):
for col in range(cols):
for row in range(rows):
array[col,row] = f(col,row)
In [13]:
%timeit nestloop(cols,rows)
100000 loops, best of 3: 17.4 µs per loop
In [14]:
array.T
Out[14]:
array([[(5532500.0, 804500.0), (5537500.0, 804500.0), (5542500.0, 804500.0)],
[(5532500.0, 799500.0), (5537500.0, 799500.0), (5542500.0, 799500.0)],
[(5532500.0, 794500.0), (5537500.0, 794500.0), (5542500.0, 794500.0)],
[(5532500.0, 789500.0), (5537500.0, 789500.0), (5542500.0, 789500.0)]], dtype=object)
但是很想学习,我该如何优化呢?我正在考虑向量化或使用 lambda。我尝试将其矢量化如下:
array[:,:] = np.vectorize(check)(cols,rows)
ValueError: could not broadcast input array from shape (2) into shape (3,4)
但是,我遇到了广播错误。当前数组为 3 x 4,但这也可以变为 3000 x 4000。
最佳答案
当然,您计算 x 和 y 坐标的方式效率非常低,因为它根本没有矢量化。你可以这样做:
In [1]: import numpy as np
In [2]: extent = (5530000.0, 5000.0, 0.0, 807000.0, 0.0, -5000.0)
...: x_steps = np.array([0,1,2]) * extent[1]
...: y_steps = np.array([0,1,2,3]) * extent[-1]
...:
In [3]: x_coords = extent[0] + x_steps + extent[1]/2
...: y_coords = extent[3] + y_steps + extent[-1]/2
...:
In [4]: x_coords
Out[4]: array([ 5532500., 5537500., 5542500.])
In [5]: y_coords
Out[5]: array([ 804500., 799500., 794500., 789500.])
此时点的坐标由笛卡尔product()给出这两个数组的:
In [5]: list(it.product(x_coords, y_coords))
Out[5]: [(5532500.0, 804500.0), (5532500.0, 799500.0), (5532500.0, 794500.0), (5532500.0, 789500.0), (5537500.0, 804500.0), (5537500.0, 799500.0), (5537500.0, 794500.0), (5537500.0, 789500.0), (5542500.0, 804500.0), (5542500.0, 799500.0), (5542500.0, 794500.0), (5542500.0, 789500.0)]
您只需将它们按 4 乘 4 分组即可。
要使用 numpy 获取产品,您可以执行以下操作(基于 this 答案):
In [6]: np.transpose([np.tile(x_coords, len(y_coords)), np.repeat(y_coords, len(x_coords))])
Out[6]:
array([[ 5532500., 804500.],
[ 5537500., 804500.],
[ 5542500., 804500.],
[ 5532500., 799500.],
[ 5537500., 799500.],
[ 5542500., 799500.],
[ 5532500., 794500.],
[ 5537500., 794500.],
[ 5542500., 794500.],
[ 5532500., 789500.],
[ 5537500., 789500.],
[ 5542500., 789500.]])
可以 reshape :
In [8]: product.reshape((3,4,2)) # product is the result of the above
Out[8]:
array([[[ 5532500., 804500.],
[ 5537500., 804500.],
[ 5542500., 804500.],
[ 5532500., 799500.]],
[[ 5537500., 799500.],
[ 5542500., 799500.],
[ 5532500., 794500.],
[ 5537500., 794500.]],
[[ 5542500., 794500.],
[ 5532500., 789500.],
[ 5537500., 789500.],
[ 5542500., 789500.]]])
如果这不是您想要的顺序,您可以执行以下操作:
In [9]: ar = np.zeros((3,4,2), float)
...: ar[0] = product[::3]
...: ar[1] = product[1::3]
...: ar[2] = product[2::3]
...:
In [10]: ar
Out[10]:
array([[[ 5532500., 804500.],
[ 5532500., 799500.],
[ 5532500., 794500.],
[ 5532500., 789500.]],
[[ 5537500., 804500.],
[ 5537500., 799500.],
[ 5537500., 794500.],
[ 5537500., 789500.]],
[[ 5542500., 804500.],
[ 5542500., 799500.],
[ 5542500., 794500.],
[ 5542500., 789500.]]])
我相信有更好的方法来完成最后的 reshape ,但我不是 numpy 专家。
请注意,使用 object 作为数据类型会带来巨大的性能损失,因为 numpy 无法优化任何内容(有时比使用正常的列表)。我使用了 (3,4,2) 数组来代替,它允许更快的操作。
关于python - 优化使用数组索引作为函数的嵌套 for 循环,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/20344908/