我看到许多机器学习教程通过构造两个矩阵、权重矩阵和输入(或激活)矩阵来解释全连接网络,并执行矩阵到矩阵乘法(matmul)以形成线性方程。
我看到的所有示例都将输入作为 matmul 的第一个参数,将权重张量作为第二个参数。这是为什么?为什么我不能执行权重乘以输入(假设权重矩阵已正确创建,列数等于输入矩阵行数)?
最佳答案
要获得 (nx1) 输出 对于 (nx1) 输入,您应该将输入与左侧的 (nxn) 矩阵或右侧的 (1x1) 矩阵相乘。
如果将输入与标量((1x1) 矩阵)相乘,则每个神经元从输入到输出都有一个连接。如果将其与矩阵相乘,对于每个输出单元,我们会得到输入神经元的加权和。换句话说,输入中的每个神经元都连接到输出中的每个神经元,并且完全连接。
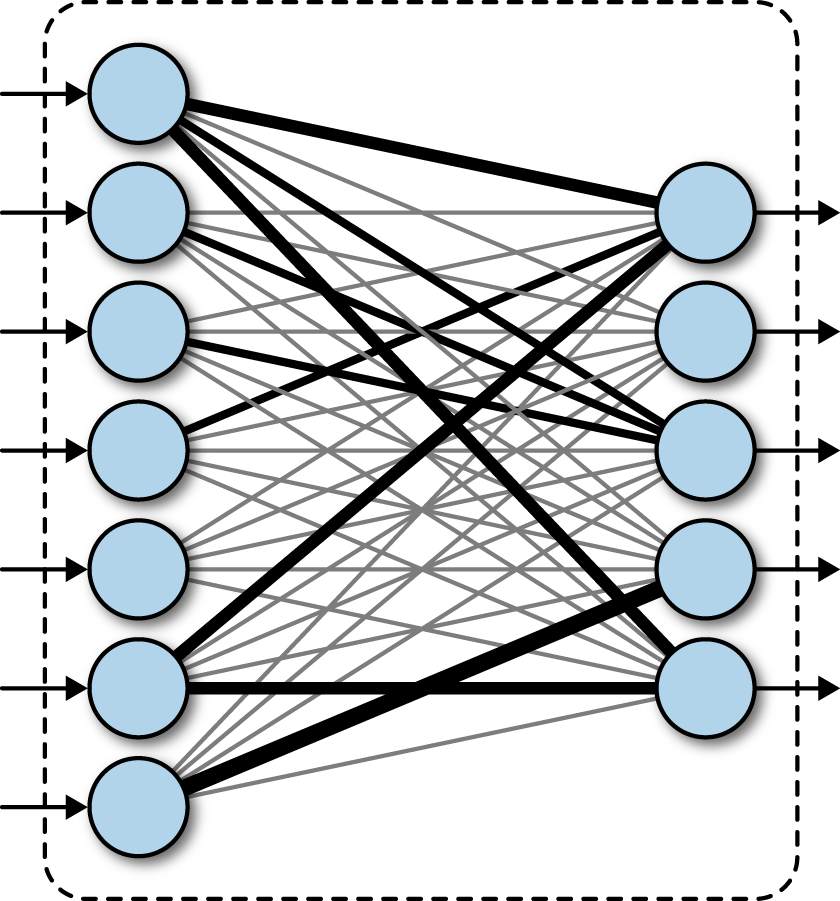
通过保留此逻辑,如何排列权重矩阵并不重要。
关于machine-learning - Matmul 输入和权重矩阵顺序?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/59548959/