我正在尝试对函数进行简单的非线性回归;使用 TensorFlow 的 x2sin(x)。请参阅下面的代码和输出。我还尝试过 a) 将样本点数量增加到 10,000,b) 增加隐藏层数量,c) 增加/减少学习率,以及 d) tanh 代替 ReLU,但没有任何改进。有人可以尝试一下,看看这种方法有什么问题吗?
import numpy as np
import tensorflow as tf
from matplotlib import pyplot as plt
import time
n = 1000
x = np.linspace(0,3.14,n)
x = np.array(x).astype(np.float32)
y = np.sin(x) * np.multiply(x, x)
r = np.random.random(n)
y = y + r
xNorm = (x - np.mean(x)) / (np.amax(x) - np.amin(x))
idxs = np.array(range(n)).astype(np.int32)
tmp = np.zeros((1, n), dtype=np.float32)
tmp[0] = xNorm
xNorm = tmp.T
print(xNorm.shape)
# Shuffle the indexes
np.random.shuffle(idxs)
# Assign 1/6th for validation, and test and the rest for training
nValidIdxs = int(n / 6)
nTestIdxs = int(n / 6)
validIdxs = idxs[0:nValidIdxs]
testIdxs = idxs[nValidIdxs:nValidIdxs + nTestIdxs]
nTrainIdxs = n - nValidIdxs - nTestIdxs
trainIdxs = idxs[nValidIdxs + nTestIdxs:n]
print('Training data points: %d' % nTrainIdxs)
print('Validation data points: %d' % nValidIdxs)
print('Testing data points: %d' % nTestIdxs)
# Split input and output values into the
# training, testing, and validation datasets.
trainX = xNorm[trainIdxs]
testX = xNorm[testIdxs]
validX = xNorm[validIdxs]
trainY = y[trainIdxs]
testY = y[testIdxs]
validY = y[validIdxs]
# This part defines a Neural Network with regularization
# applied to the loss term. SGD batch size is 128 samples.
# In addition, dropout is applied to the hidden layers during
# the training process.
batchSize = 256
nNodes = 20
stdDev = 0.001
regParam = 0.0001
initRate = 0.0001
nLayers = 1
graph = tf.Graph()
tf.set_random_seed(1234)
with graph.as_default():
# Input data. For the training data, we use a placeholder that will be fed
# at run time with a training minibatch.
tfTrainX = tf.placeholder(tf.float32, shape=(batchSize, 1))
tfTrainY = tf.placeholder(tf.float32, shape=(batchSize))
tfValidX = tf.constant(validX)
tfTestX = tf.constant(testX)
tfAllX = tf.constant(xNorm)
# This function defines a deep neural network
# with 3 hidden layers and one output layer.
def deepNeural(dataset):
w = []
b = []
for i in range(nLayers):
w.append(None)
b.append(None)
# Hidden layers
for i in range(nLayers):
if(i == 0):
w[i] = tf.Variable(
tf.truncated_normal([1, nNodes], stddev=stdDev))
logits = tf.matmul(dataset, w[i])
else:
w[i] = tf.Variable(
tf.truncated_normal([nNodes, nNodes], stddev=stdDev))
logits = tf.matmul(logits, w[i])
b[i] = tf.Variable(tf.zeros([nNodes]))
logits = tf.add(logits, b[i])
logits = tf.nn.relu(logits)
# Output layer
wo = tf.ones([nNodes, 1], tf.float32)
logits = tf.matmul(logits, wo)
# Return the output layer
return [logits, w, b, wo]
# This function provides the logits from the output
# layer calculated based upon the passed weights and
# biases for the hidden and output layer calculated
# based upon the loss minimization.
def predict(dataset, w, b, wo):
# Computation for hidden layers
for i in range(nLayers):
if(i == 0):
logits = tf.matmul(dataset, w[i])
else:
logits = tf.matmul(logits, w[i])
logits = tf.add(logits, b[i])
logits = tf.nn.relu(logits)
# Computation for the output layer
return tf.matmul(logits, wo)
logits, w, b, wo = deepNeural(tfTrainX)
loss = 0.5 * tf.reduce_mean(tf.square(logits - tfTrainY))
# Compute regularization term
regTerm = tf.Variable(0.0)
for i in range(nLayers):
regTerm = regTerm + tf.reduce_mean(tf.nn.l2_loss(w[i]))
regTerm = regTerm * regParam
# Add regularization term to loss
loss = loss + regTerm
# Optimizer.
# Exponential decay of learning rate.
globalStep = tf.Variable(0) # count the number of steps taken.
learningRate = tf.train.exponential_decay(initRate, globalStep, 500, 0.96, staircase=True)
optimizer = tf.train.GradientDescentOptimizer(learningRate).minimize(loss)
# Predictions for the training, validation, and test data.
trainPred = logits
validPred = predict(tfValidX, w, b, wo)
testPred = predict(tfTestX, w, b, wo)
allPred = predict(tfAllX, w, b, wo)
def rmse(pred, actual):
#print(pred.shape)
pred = pred.reshape(1,-1)
actual = actual.reshape(1,-1)
return np.sqrt(((pred - actual)**2).mean())
# Run SGD for Neural Network with regularization
numSteps = 5001
startTime = time.time()
predY = np.array([])
validRMSEOld = 0.0
with tf.Session(graph=graph) as session:
tf.global_variables_initializer().run()
print("Initialized")
for step in range(numSteps):
# Pick an offset within the training data, which has been randomized.
# Note: we could use better randomization across epochs.
offset = (step * batchSize) % (trainY.shape[0] - batchSize)
# Generate a minibatch.
batchX = trainX[offset:(offset + batchSize), :]
batchY = trainY[offset:(offset + batchSize)]
# Prepare a dictionary telling the session where to feed the minibatch.
# The key of the dictionary is the placeholder node of the graph to be fed,
# and the value is the numpy array to feed to it.
feedDict = {tfTrainX : batchX, tfTrainY : batchY}
_, l, pred = session.run(
[optimizer, loss, trainPred], feed_dict=feedDict)
if (step % 500 == 0):
print("Minibatch loss at step %d: %f" % (step, l))
print("Minibatch RMSE: %f" % rmse(pred, batchY))
validRMSE = rmse(validPred.eval(), validY)
print("Validation RMSE: %f" % validRMSE)
relChange = (validRMSEOld - validRMSE) / validRMSEOld
if (abs(relChange) < 0.0001 or np.isnan(validRMSE)):
break
else:
validRMSEOld = validRMSE
print("Test RMSE: %f" % rmse(testPred.eval(), testY))
print("Total RMSE: %f" % rmse(allPred.eval(), y))
predY = allPred.eval()
print('Execution time: %f' % (time.time() - startTime))
plt.plot(y, 'ro')
plt.plot(predY, '-', lw=3)
输出:
(1000, 1)
训练数据点:668
验证数据点:166
测试数据点:166
已初始化
第 0 步的小批量损失:3.902083
小批量 RMSE:2.793586
验证 RMSE:2.771836
第 500 步的小批量损失:1.504731
小批量 RMSE:1.733019
验证 RMSE:1.693558
第 1000 步的小批量损失:1.077074
小批量 RMSE:1.465299
验证 RMSE:1.492440
第 1500 步的小批量损失:1.064864
小批量 RMSE:1.456898
验证 RMSE:1.464581
第 2000 步的小批量损失:1.060161
小批量 RMSE:1.453716
验证 RMSE:1.461370
第 2500 步的小批量损失:1.055446
小批量 RMSE:1.450549
验证 RMSE:1.461191
第 3000 步的小批量损失:1.069557
小批量 RMSE:1.460215
验证 RMSE:1.461298
测试 RMSE:1.557867
总 RMSE:1.473936
执行时间:10.608121
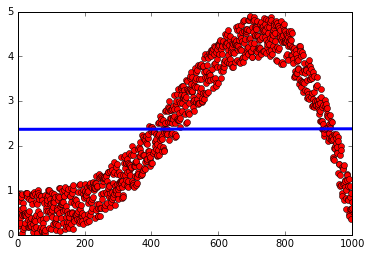{kind=link}
最佳答案
以下修改后的代码有效。主要问题是损失函数,它应该是 loss = 0.5 * tf.reduce_mean(tf.square(tf.transpose(logits) - tfTrainY))
import numpy as np
import tensorflow as tf
from matplotlib import pyplot as plt
import time
n = 10000
x = np.linspace(0,3.14,n)
x = np.array(x).astype(np.float32)
y = np.sin(x) * np.multiply(x, x)
r = np.random.random(n)
y = y + r
xNorm = (x - np.mean(x)) / (np.amax(x) - np.amin(x))
idxs = np.array(range(n)).astype(np.int32)
tmp = np.zeros((1, n), dtype=np.float32)
tmp[0] = xNorm
xNorm = tmp.T
print(xNorm.shape)
# Shuffle the indexes
np.random.shuffle(idxs)
# Assign 1/6th for validation, and test and the rest for training
nValidIdxs = int(n / 6)
nTestIdxs = int(n / 6)
validIdxs = idxs[0:nValidIdxs]
testIdxs = idxs[nValidIdxs:nValidIdxs + nTestIdxs]
nTrainIdxs = n - nValidIdxs - nTestIdxs
trainIdxs = idxs[nValidIdxs + nTestIdxs:n]
print('Training data points: %d' % nTrainIdxs)
print('Validation data points: %d' % nValidIdxs)
print('Testing data points: %d' % nTestIdxs)
# Split input and output values into the
# training, testing, and validation datasets.
trainX = xNorm[trainIdxs]
testX = xNorm[testIdxs]
validX = xNorm[validIdxs]
trainY = y[trainIdxs]
testY = y[testIdxs]
validY = y[validIdxs]
# This part defines a Neural Network with regularization
# applied to the loss term. SGD batch size is 128 samples.
# In addition, dropout is applied to the hidden layers during
# the training process.
batchSize = 256
nNodes = 128
stdDev = 0.1
regParam = 0.0001
initRate = 0.001
nLayers = 3
graph = tf.Graph()
tf.set_random_seed(1234)
with graph.as_default():
# Input data. For the training data, we use a placeholder that will be fed
# at run time with a training minibatch.
tfTrainX = tf.placeholder(tf.float32, shape=(batchSize, 1))
tfTrainY = tf.placeholder(tf.float32, shape=(batchSize))
tfValidX = tf.constant(validX)
tfTestX = tf.constant(testX)
tfAllX = tf.constant(xNorm)
# This function defines a deep neural network
# with 3 hidden layers and one output layer.
def deepNeural(dataset):
w = []
b = []
for i in range(nLayers):
w.append(None)
b.append(None)
# Hidden layers
for i in range(nLayers):
if(i == 0):
w[i] = tf.Variable(
tf.truncated_normal([1, nNodes], stddev=stdDev))
logits = tf.matmul(dataset, w[i])
else:
w[i] = tf.Variable(
tf.truncated_normal([nNodes, nNodes], stddev=stdDev))
logits = tf.matmul(logits, w[i])
b[i] = tf.Variable(tf.zeros([nNodes]))
logits = tf.add(logits, b[i])
logits = tf.nn.tanh(logits)
# Output layer
wo = tf.ones([nNodes, 1], tf.float32)
logits = tf.matmul(logits, wo)
# Return the output layer
return [logits, w, b, wo]
# This function provides the logits from the output
# layer calculated based upon the passed weights and
# biases for the hidden and output layer calculated
# based upon the loss minimization.
def predict(dataset, w, b, wo):
# Computation for hidden layers
for i in range(nLayers):
if(i == 0):
logits = tf.matmul(dataset, w[i])
else:
logits = tf.matmul(logits, w[i])
logits = tf.add(logits, b[i])
logits = tf.nn.tanh(logits)
# Computation for the output layer
return tf.matmul(logits, wo)
logits, w, b, wo = deepNeural(tfTrainX)
loss = 0.5 * tf.reduce_mean(tf.square(tf.transpose(logits) - tfTrainY))
# Compute regularization term
regTerm = tf.Variable(0.0)
for i in range(nLayers):
regTerm = regTerm + tf.reduce_mean(tf.nn.l2_loss(w[i]))
regTerm = regTerm * regParam
# Add regularization term to loss
loss = loss + regTerm
# Optimizer.
# Exponential decay of learning rate.
globalStep = tf.Variable(0) # count the number of steps taken.
learningRate = tf.train.exponential_decay(initRate, globalStep, 1000, 0.96, staircase=True)
optimizer = tf.train.AdamOptimizer(learningRate).minimize(loss)
# Predictions for the training, validation, and test data.
trainPred = logits
validPred = predict(tfValidX, w, b, wo)
testPred = predict(tfTestX, w, b, wo)
allPred = predict(tfAllX, w, b, wo)
def rmse(pred, actual):
#print(pred.shape)
pred = pred.reshape(1,-1)
actual = actual.reshape(1,-1)
return np.sqrt(((pred - actual)**2).mean())
# Run SGD for Neural Network with regularization
numSteps = 10001
startTime = time.time()
predY = np.array([])
validRMSEOld = 0.0
with tf.Session(graph=graph) as session:
tf.global_variables_initializer().run()
print("Initialized")
for step in range(numSteps):
# Pick an offset within the training data, which has been randomized.
# Note: we could use better randomization across epochs.
offset = (step * batchSize) % (trainY.shape[0] - batchSize)
# Generate a minibatch.
batchX = trainX[offset:(offset + batchSize), :]
batchY = trainY[offset:(offset + batchSize)]
# Prepare a dictionary telling the session where to feed the minibatch.
# The key of the dictionary is the placeholder node of the graph to be fed,
# and the value is the numpy array to feed to it.
feedDict = {tfTrainX : batchX, tfTrainY : batchY}
_, l, pred = session.run(
[optimizer, loss, trainPred], feed_dict=feedDict)
if (step % 1000 == 0):
print("Minibatch loss at step %d: %f" % (step, l))
print("Minibatch RMSE: %f" % rmse(pred, batchY))
validRMSE = rmse(validPred.eval(), validY)
print("Validation RMSE: %f" % validRMSE)
relChange = (validRMSEOld - validRMSE) / validRMSEOld
if (abs(relChange) < 0.0001 or np.isnan(validRMSE)):
break
else:
validRMSEOld = validRMSE
print("Test RMSE: %f" % rmse(testPred.eval(), testY))
print("Total RMSE: %f" % rmse(allPred.eval(), y))
predY = allPred.eval()
print('Execution time: %f' % (time.time() - startTime))
plt.plot(y, 'ro')
plt.plot(predY, '-', lw=5)
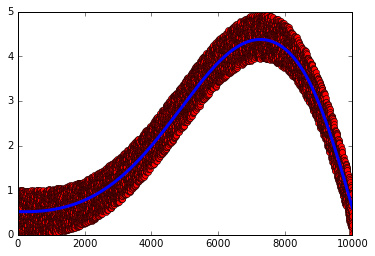{kind=link}
关于machine-learning - 使用 TensorFlow 进行非线性回归,结果呈直线,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/40983530/