关闭。这个问题不满足Stack Overflow guidelines .它目前不接受答案。
想改善这个问题吗?更新问题,使其成为 on-topic对于堆栈溢出。
9 个月前关闭。
Improve this question
我知道关于什么是交叉熵有很多解释,但我仍然很困惑。
只是描述损失函数的一种方法吗?我们可以使用梯度下降算法使用损失函数找到最小值吗?
最佳答案
交叉熵通常用于量化两个概率分布之间的差异。在机器学习的背景下,它是分类多类分类问题的误差度量。通常,“真实”分布(您的机器学习算法试图匹配的分布)表示为 one-hot 分布。
例如,假设对于特定的训练实例,真实标签是 B(在可能的标签 A、B 和 C 中)。因此,此训练实例的 one-hot 分布是:
Pr(Class A) Pr(Class B) Pr(Class C)
0.0 1.0 0.0
现在,假设您的机器学习算法预测以下概率分布:
Pr(Class A) Pr(Class B) Pr(Class C)
0.228 0.619 0.153

其中
p(x) 是真实概率分布(one-hot),q(x) 是预测概率分布。总和是 A、B 和 C 三个类的总和。在这种情况下,损失为 0.479 :H = - (0.0*ln(0.228) + 1.0*ln(0.619) + 0.0*ln(0.153)) = 0.479
请注意,只要您始终使用相同的对数底,使用何种对数底并不重要。碰巧的是,Python Numpy
log() 函数计算自然对数(以 e 为底的对数)。Python代码
下面是使用 Numpy 在 Python 中表达的上述示例:
import numpy as np
p = np.array([0, 1, 0]) # True probability (one-hot)
q = np.array([0.228, 0.619, 0.153]) # Predicted probability
cross_entropy_loss = -np.sum(p * np.log(q))
print(cross_entropy_loss)
# 0.47965000629754095
损失单位
我们在上面的例子中看到损失是 0.4797。因为我们使用的是自然对数(log base e),单位是 nats ,所以我们说损失是 0.4797 nats。如果日志是以 2 为基数的日志,则单位为位。请参阅 this page 以获取进一步说明。
更多例子
为了更直观地了解这些损失值所反射(reflect)的内容,让我们看一些极端的例子。
同样,让我们假设真正的(one-hot)分布是:
Pr(Class A) Pr(Class B) Pr(Class C)
0.0 1.0 0.0
Pr(Class A) Pr(Class B) Pr(Class C)
0.001 0.998 0.001
p = np.array([0, 1, 0])
q = np.array([0.001, 0.998, 0.001])
print(-np.sum(p * np.log(q)))
# 0.0020020026706730793
Pr(Class A) Pr(Class B) Pr(Class C)
0.001 0.001 0.998
p = np.array([0, 1, 0])
q = np.array([0.001, 0.001, 0.998])
print(-np.sum(p * np.log(q)))
# 6.907755278982137
Pr(Class A) Pr(Class B) Pr(Class C)
0.333 0.333 0.334
p = np.array([0, 1, 0])
q = np.array([0.333, 0.333, 0.334])
print(-np.sum(p * np.log(q)))
# 1.0996127890016931
交叉熵是许多可能的损失函数之一(另一个流行的是 SVM 铰链损失)。这些损失函数通常写为 J(theta),可用于梯度下降,这是一种将参数(或系数)移向最佳值的迭代算法。在下面的等式中,您将
J(theta) 替换为 H(p, q) 。但请注意,您需要先计算 H(p, q) 对参数的导数。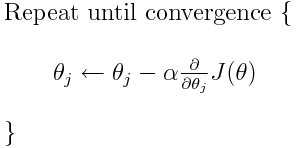
因此,要直接回答您的原始问题:
Is it only a method to describe the loss function?
正确的交叉熵描述了两个概率分布之间的损失。它是许多可能的损失函数之一。
Then we can use, for example, gradient descent algorithm to find the minimum.
是的,交叉熵损失函数可以用作梯度下降的一部分。
进一步阅读:我的一个与 TensorFlow 相关的 other answers。
关于machine-learning - 什么是交叉熵?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/41990250/