我有一个 Pandas 数据框:
import pandas as pd
import numpy as np
df = pd.DataFrame(columns=['Text','Selection_Values'])
df["Text"] = ["Hi", "this is", "just", "a", "single", "sentence.", "This", np.nan, "is another one.","This is", "a", "third", "sentence","."]
df["Selection_Values"] = [0,0,0,0,0,1,0,0,1,0,0,0,0,0]
print(df)
输出:
Text Selection_Values
0 Hi 0
1 this is 0
2 just 0
3 a 0
4 single 0
5 sentence. 1
6 This 0
7 NaN 0
8 is another one. 1
9 This is 0
10 a 0
11 third 0
12 sentence 0
13 . 0
现在,我想根据 Selection Value 列将 Text 列重新组合到一个二维数组中。出现在 0(第一个整数,或 1 之后)和 1(包括)之间的所有单词都应放入二维数组中.数据集的最后一句话可能没有结束 1。这可以按照这个问题中的解释来完成:Regroup pandas column into 2D list based on another column
[["Hi this is just a single sentence."],["This is another one"], ["This is a third sentence ."]]
我想更进一步,提出以下条件:如果一个列表中有超过 max_number_of_cells_per_list 个非 NaN 单元格,那么这个列表应该分成大致相等的最多包含 +/- 1 个 max_number_of_cells_per_list 单元格元素的部分。
假设:max_number_of_cells_per_list = 2,那么预期的输出应该是:
[["Hi this is"], ["just a"], ["single sentence."],["This is another one"], ["This is"], ["a third sentence ."]]
示例:
基于“Selection_Values”列,可以将单元格重新组合到以下二维列表中,使用:
[[s.str.cat(sep=' ')] for s in np.split(df.Text, df[df.Selection_Values == 1].index+1) if not s.empty]
输出(原始列表):
[["Hi this is just a single sentence."],["This is another one"], ["This is a third sentence ."]]
让我们看一下这些列表中的单元格数量:
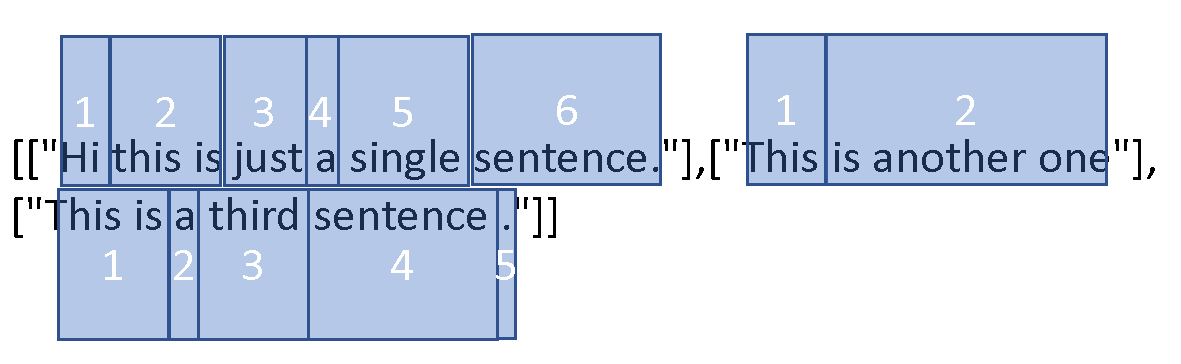
如您所见,列表 1 有 6 个单元格,列表 2 有 2 个单元格,列表 3 有 5 个单元格。
现在,我想要实现的是:如果列表中的单元格数量超过一定数量,则应将其拆分,以便每个结果列表具有 +/-1 所需数量的单元格.
例如 max_number_of_cells_per_list = 2
修改列表:
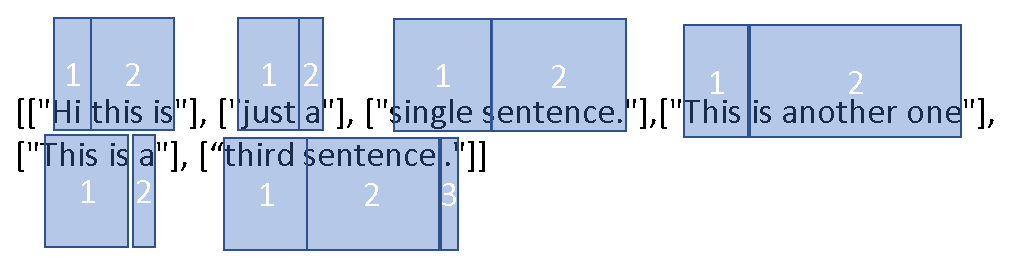
你有办法做到这一点吗?
编辑: 重要说明:原始列表中的单元格不应放入相同的列表中。
编辑 2:
Text Selection_Values New
0 Hi 0 1.0
1 this is 0 0.0
2 just 0 1.0
3 a 0 0.0
4 single 0 1.0
5 sentence. 1 0.0
6 This 0 1.0
7 NaN 0 0.0
8 is another one. 1 1.0
9 This is 0 0.0
10 a 0 1.0
11 third 0 0.0
12 sentence 0 0.0
13 . 0 NaN
最佳答案
IIUC,你可以这样做:
n=2 #change this as you like for no. of splits
s=df.Text.dropna().reset_index(drop=True)
c=s.groupby(s.index//n).cumcount().eq(0).shift().shift(-1).fillna(False)
[[i] for i in s.groupby(c.cumsum()).apply(' '.join).tolist()]
[['Hi this is'], ['just a'], ['single sentence.'],
['This is another one.'], ['This is a'], ['third sentence .']]
编辑:
d=dict(zip(df.loc[df.Text.notna(),'Text'].index,c.index))
ser=pd.Series(d)
df['new']=ser.reindex(range(ser.index.min(),
ser.index.max()+1)).map(c).fillna(False).astype(int)
print(df)
Text Selection_Values new
0 Hi 0 1
1 this is 0 0
2 just 0 1
3 a 0 0
4 single 0 1
5 sentence. 1 0
6 This 0 1
7 NaN 0 0
8 is another one. 1 0
9 This is 0 1
10 a 0 0
11 third 0 1
12 sentence 0 0
13 . 0 0
关于python - 从 Pandas 数据框构建二维数组,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/57132815/