我有一个多索引 DataFrame,如下所示:
In[114]: cdm
Out[114]:
Last TD
Date Ticker
1983-03-30 CLM83 29.40 44
CLN83 29.35 76
CLQ83 29.20 105
CLU83 28.95 139
CLV83 28.95 167
CLX83 28.90 197
CLZ83 28.75 230
1983-03-31 CLM83 29.29 43
CLN83 29.24 75
CLQ83 29.05 104
CLU83 28.85 138
CLV83 28.75 166
CLX83 28.70 196
CLZ83 28.60 229
1983-04-04 CLM83 29.44 39
CLN83 29.25 71
CLQ83 29.10 100
CLU83 29.05 134
CLV83 28.95 162
CLX83 28.95 192
CLZ83 28.85 225
1983-04-05 CLM83 29.71 38
CLN83 29.54 70
CLQ83 29.35 99
CLU83 29.20 133
CLV83 29.10 161
CLX83 29.00 191
CLZ83 29.00 224
1983-04-06 CLM83 29.90 37
CLN83 29.68 69
... ...
2016-07-05 CLV6 47.91 72
CLX6 48.51 104
CLZ6 49.07 134
CLF7 49.54 163
CLG7 49.93 196
CLH7 50.26 226
CLJ7 50.53 254
CLK7 50.77 286
CLM7 51.00 316
CLN7 51.20 345
CLQ7 51.39 377
CLU7 51.58 408
CLV7 51.79 437
CLX7 52.03 469
2016-07-06 CLQ6 47.43 9
CLU6 48.14 42
CLV6 48.75 71
CLX6 49.34 103
CLZ6 49.89 133
CLF7 50.36 162
CLG7 50.75 195
CLH7 51.08 225
CLJ7 51.35 253
CLK7 51.60 285
CLM7 51.84 315
CLN7 52.05 344
CLQ7 52.25 376
CLU7 52.46 407
CLV7 52.69 436
CLX7 52.94 468
[289527 rows x 2 columns]
它相当大,我想重新设置价格基准,这意味着在每个时间点(每个“日期”)第一个价格(“最后”)设置为 100,其他价格根据第一个价格进行衡量.
我有以下功能:
def rebase(prices):
return prices/prices[0]*100
我还想出了一个 groupby 方法来实现我的目标。然而它太长了:
%time cdm.groupby(level='Date')['Last'].apply(rebase)
Wall time: 1min 49s
Out[115]:
Date Ticker
1983-03-30 CLM83 100.000000
CLN83 99.829932
CLQ83 99.319728
CLU83 98.469388
CLV83 98.469388
CLX83 98.299320
CLZ83 97.789116
1983-03-31 CLM83 100.000000
CLN83 99.829293
CLQ83 99.180608
CLU83 98.497781
CLV83 98.156367
CLX83 97.985661
CLZ83 97.644247
1983-04-04 CLM83 100.000000
CLN83 99.354620
CLQ83 98.845109
CLU83 98.675272
CLV83 98.335598
CLX83 98.335598
CLZ83 97.995924
1983-04-05 CLM83 100.000000
CLN83 99.427802
CLQ83 98.788287
CLU83 98.283406
CLV83 97.946819
CLX83 97.610232
CLZ83 97.610232
1983-04-06 CLM83 100.000000
CLN83 99.264214
2016-07-05 CLV6 102.811159
CLX6 104.098712
CLZ6 105.300429
CLF7 106.309013
CLG7 107.145923
CLH7 107.854077
CLJ7 108.433476
CLK7 108.948498
CLM7 109.442060
CLN7 109.871245
CLQ7 110.278970
CLU7 110.686695
CLV7 111.137339
CLX7 111.652361
2016-07-06 CLQ6 100.000000
CLU6 101.496943
CLV6 102.783049
CLX6 104.026987
CLZ6 105.186591
CLF7 106.177525
CLG7 106.999789
CLH7 107.695551
CLJ7 108.264811
CLK7 108.791904
CLM7 109.297913
CLN7 109.740670
CLQ7 110.162345
CLU7 110.605102
CLV7 111.090027
CLX7 111.617120
Name: Last, dtype: float64
完成它需要 1.30 到 3 分钟,而且我仍然需要进行更多操作才能到达我想要的位置,即将这一列重新定价的价格包含在我的第一个 DataFrame cdm 中:
groupRebP = cdm.groupby(level='Date')['Last'].apply(rebase)
groupRebP = pd.DataFrame(groupRebP)
cdm['RebP'] = groupRebP['Last']
是否有更快、更 pythonic 的方法来实现这一目标?
谢谢你的建议,
最佳答案
设置
from StringIO import StringIO
import pandas as pd
import numpy as np
text = """Date Ticker Last TD
1983-03-30 CLM83 29.40 44
1983-03-30 CLN83 29.35 76
1983-03-30 CLQ83 29.20 105
1983-03-30 CLU83 28.95 139
1983-03-30 CLV83 28.95 167
1983-03-30 CLX83 28.90 197
1983-03-30 CLZ83 28.75 230
1983-03-31 CLM83 29.29 43
1983-03-31 CLN83 29.24 75
1983-03-31 CLQ83 29.05 104
1983-03-31 CLU83 28.85 138
1983-03-31 CLV83 28.75 166
1983-03-31 CLX83 28.70 196
1983-03-31 CLZ83 28.60 229
1983-04-04 CLM83 29.44 39
1983-04-04 CLN83 29.25 71
1983-04-04 CLQ83 29.10 100
1983-04-04 CLU83 29.05 134
1983-04-04 CLV83 28.95 162
1983-04-04 CLX83 28.95 192
1983-04-04 CLZ83 28.85 225
1983-04-05 CLM83 29.71 38
1983-04-05 CLN83 29.54 70
1983-04-05 CLQ83 29.35 99
1983-04-05 CLU83 29.20 133
1983-04-05 CLV83 29.10 161
1983-04-05 CLX83 29.00 191
1983-04-05 CLZ83 29.00 224"""
cdm = pd.read_csv(StringIO(text),
delim_whitespace=True,
parse_dates=[0],
index_col=[0, 1])
解决方案
经常使用numpy!
cdm_last = cdm.Last.unstack()
a = cdm_last.values
a_rebased = np.concatenate([np.ones((1, a.shape[1])),
np.exp(np.diff(np.log(a), axis=0))]) * 100
cdm_last_rebased = pd.DataFrame(a_rebased, cdm_last.index, cdm_last.columns)
cdm_last_rebased
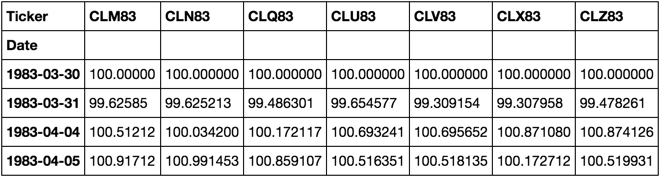
stack 返回您的系列。
cdm_last_rebased.stack()
Date Ticker
1983-03-30 CLM83 100.000000
CLN83 100.000000
CLQ83 100.000000
CLU83 100.000000
CLV83 100.000000
CLX83 100.000000
CLZ83 100.000000
1983-03-31 CLM83 99.625850
CLN83 99.625213
CLQ83 99.486301
CLU83 99.654577
CLV83 99.309154
CLX83 99.307958
CLZ83 99.478261
1983-04-04 CLM83 100.512120
CLN83 100.034200
CLQ83 100.172117
CLU83 100.693241
CLV83 100.695652
CLX83 100.871080
CLZ83 100.874126
1983-04-05 CLM83 100.917120
CLN83 100.991453
CLQ83 100.859107
CLU83 100.516351
CLV83 100.518135
CLX83 100.172712
CLZ83 100.519931
dtype: float64
关于python - 基于多索引 DataFrame 的水平重新设定价格的最 pythonic 方法是什么?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/39254229/