我遵循了GPU Pro Tip: CUDA 7 Streams Simplify Concurrency中提供的方法并在 VS2013 中使用 CUDA 7.5 对其进行了测试。虽然多流示例有效,但多线程示例没有给出预期的结果。代码如下:
#include <pthread.h>
#include <cstdio>
#include <cmath>
#define CUDA_API_PER_THREAD_DEFAULT_STREAM
#include "cuda.h"
const int N = 1 << 20;
__global__ void kernel(float *x, int n)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = tid; i < n; i += blockDim.x * gridDim.x) {
x[i] = sqrt(pow(3.14159, i));
}
}
void *launch_kernel(void *dummy)
{
float *data;
cudaMalloc(&data, N * sizeof(float));
kernel << <1, 64 >> >(data, N);
cudaStreamSynchronize(0);
return NULL;
}
int main()
{
const int num_threads = 8;
pthread_t threads[num_threads];
for (int i = 0; i < num_threads; i++) {
if (pthread_create(&threads[i], NULL, launch_kernel, 0)) {
fprintf(stderr, "Error creating threadn");
return 1;
}
}
for (int i = 0; i < num_threads; i++) {
if (pthread_join(threads[i], NULL)) {
fprintf(stderr, "Error joining threadn");
return 2;
}
}
cudaDeviceReset();
return 0;
}
我也试过在 CUDA C/C++->Host->Preprocessor Definitions 中添加 CUDA_API_PER_THREAD_DEFAULT_STREAM 宏,但结果是一样的。 Profiler生成的时间线如下:
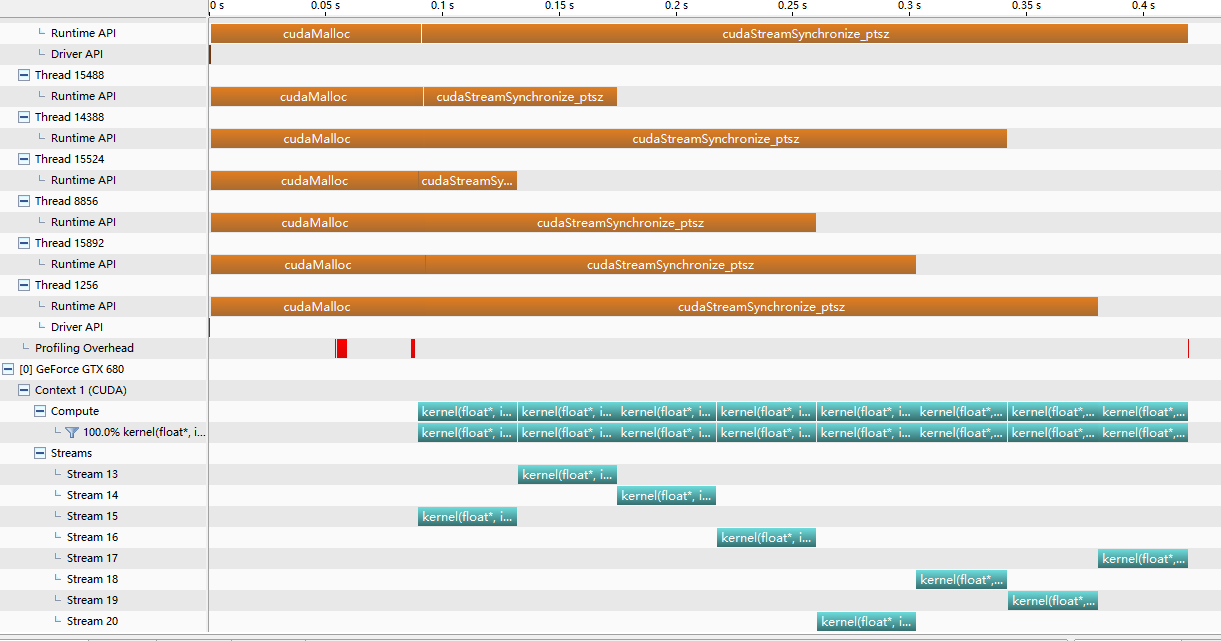
你知道这里发生了什么吗?非常感谢。
最佳答案
如您所料,您发布的代码对我有用:

当像这样在带有 CUDA 7.0 的 Linux 系统上编译和运行时:
$ nvcc -arch=sm_30 --default-stream per-thread -o thread.out thread.cu
由此我只能假设您有平台特定问题,或者您的构建方法不正确(请注意,必须为每个翻译单元指定 --default-stream per-thread构建)。
关于c++ - 如何在 Visual Studio 2013 中启用 CUDA 7.0+ 每线程默认流?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/34259948/