我正在使用 sklearn's PCA用于对大量图像进行降维。安装 PCA 后,我想看看组件的外观。
可以通过查看 components_ 属性来做到这一点。没有意识到这是可用的,我做了其他事情:
each_component = np.eye(total_components)
component_im_array = pca.inverse_transform(each_component)
for i in range(num_components):
component_im = component_im_array[i, :].reshape(height, width)
# do something with component_im
换句话说,我在 PCA 空间中创建了一个图像,除了 1 之外的所有特征都设置为 0。通过对它们进行逆变换,我应该得到原始空间中的图像,一旦变换,就可以单独表示为PCA 组件。
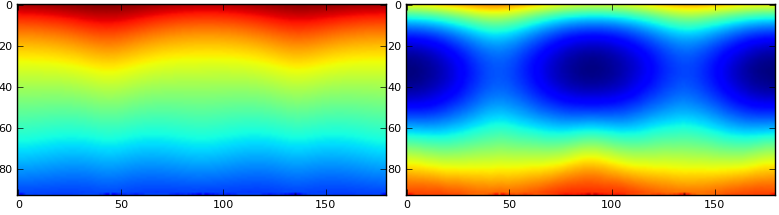
下图显示了结果。左边是用我的方法计算出来的分量。右边直接是pca.components_[i]。此外,使用我的方法,大多数图像非常相似(但它们不同),而通过访问 components_,图像与我预期的非常不同
我的方法是否存在概念性问题?显然 pca.components_[i] 中的组件比我得到的组件正确(或至少更正确)。谢谢!
最佳答案
组件和逆变换是两个不同的东西。逆变换将分量映射回原始图像空间
#Create a PCA model with two principal components
pca = PCA(2)
pca.fit(data)
#Get the components from transforming the original data.
scores = pca.transform(data)
# Reconstruct from the 2 dimensional scores
reconstruct = pca.inverse_transform(scores )
#The residual is the amount not explained by the first two components
residual=data-reconstruct
因此,您是对原始数据而不是组件进行逆变换,因此它们是完全不同的。你几乎从不 inverse_transform 原始数据。 pca.components_ 是表示用于将数据投影到 pca 空间的基础轴的实际向量。
关于python - 使用 sklearn 提取 PCA 成分,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/22126717/