我正在学习二叉搜索树教程。我找到了这个函数destroy_tree(node* leaf)。它的行为让我担心 - 我无法想象调用堆栈是什么样子,你能给我解释一下吗?
void btree::destroy_tree(node* leaf)
{
if (leaf !=NULL)
{
destroy_tree(leaf->left);
destroy_tree(leaf->right);
delete leaf;
}
}
最佳答案
对于有关递归函数的问题,有时只需思考或绘制一棵简单的树并在纸上绘制出函数如何遍历它会有所帮助。
首先,我已经有一段时间没有使用 C++ 了,但为了这个示例,我将把你的代码更改为:
void btree::destroy_tree(node* leaf)
{
if(leaf !=NULL)
{
if (leaf->left != NULL)
destroy_tree(leaf->left);
if (leaf->right != NULL)
destroy_tree(leaf->right);
delete leaf;
}
}
只是为了减少堆栈上的内容。
想想这个函数的逻辑是如何通过树递归地工作的。以我从维基百科获取的以下树为例
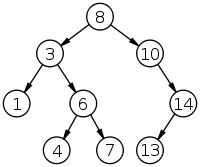 假设您调用
假设您调用 destroy_tree(root)。函数 destroy_tree(root) 首先调用 destroy_tree(node->left),然后调用 destroy_tree(node->right)。这意味着左 child 总是在任何右 child 之前被迭代。因此,要使用上述树中的数字,树将按以下顺序遍历:8,3,1,6,4,7,10,14,13。基于此你可以看到所有的左子节点都被遍历了。当仍有未遍历的左子节点时,不会遍历右子节点。
调用堆栈应该与程序运行时类似。调用 destroy_tree(left) 将在到达任何右节点之前对每个连续的左节点调用“destroy_tree()”。
关于c++ - 二叉搜索树中递归删除调用的调用堆栈是什么样的?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/18594228/