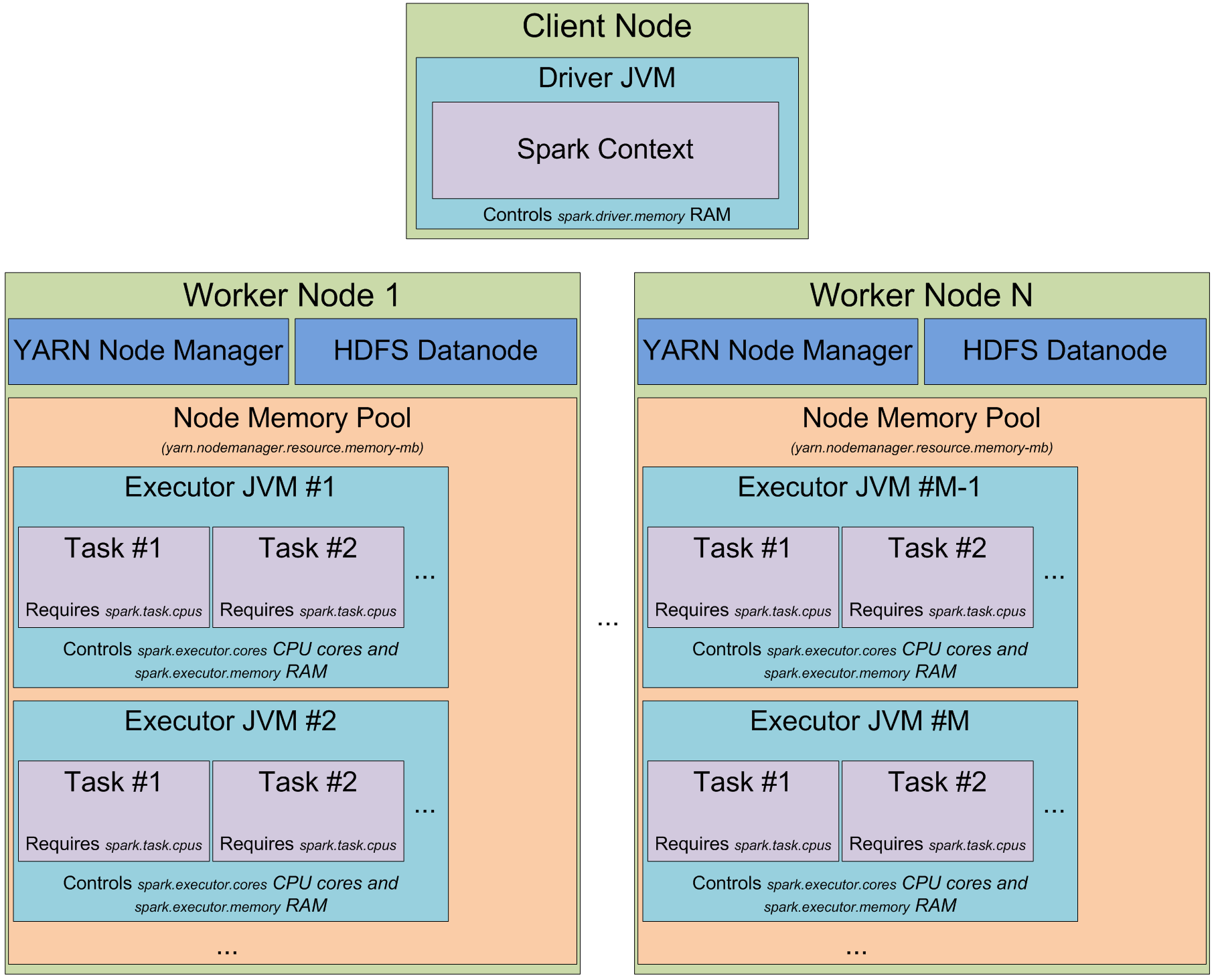
This diagram很清楚不同YARN和Spark内存相关设置之间的关系,除了spark.python.worker.memory。
{kind=link}
spark.python.worker.memory 如何适应这种内存模型?
Python 进程是由 spark.executor.memory 还是 yarn.nodemanager.resource.memory-mb 管理的?
更新
This question解释了设置的作用,但没有回答有关内存管理的问题,或者它与其他内存设置的关系。
最佳答案
Found this thread从 Apache-spark 邮件列表中,看来 spark.python.worker.memory 是 spark.executor.memory 内存的子集。
来自线程:“spark.python.worker.memory 用于执行器中的 Python worker ”
关于memory - spark.python.worker.memory 与 spark.executor.memory 有何关系?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/36594056/