我有一个像下面这样的迷宫:
||||||||||||||||||||||||||||||||||||
| P|
| ||||||||||||||||||||||| |||||||| |
| || | | ||||||| || |
| || | | | | |||| ||||||||| || |||||
| || | | | | || || |
| || | | | | | |||| ||| |||||| |
| | | | | | || |||||||| |
| || | | |||||||| || || |||||
| || | || ||||||||| || |
| |||||| ||||||| || |||||| |
|||||| | |||| || | |
| |||||| ||||| | || || |||||
| |||||| | ||||| || |
| |||||| ||||||||||| || || |
|||||||||| |||||| |
|+ |||||||||||||||| |
||||||||||||||||||||||||||||||||||||
目标是P找到+,子目标为
- 到
+的路径成本最低(1 跳 = 成本 +1) - 搜索到的单元格数量(节点扩展)被最小化
我试图理解为什么我的 A* 启发式算法的性能比我的贪心最佳优先算法的实现差得多。以下是每个代码的两位代码:
#Greedy Best First -- Manhattan Distance
self.heuristic = abs(goalNodeXY[1] - self.xy[1]) + abs(goalNodeXY[0] - self.xy[0])
#A* -- Manhattan Distance + Path Cost from 'startNode' to 'currentNode'
return abs(goalNodeXY[1] - self.xy[1]) + abs(goalNodeXY[0] - self.xy[0]) + self.costFromStart
在这两种算法中,我都使用了 heapq,根据启发值确定优先级。两者的主要搜索循环相同:
theFrontier = []
heapq.heappush(theFrontier, (stateNode.heuristic, stateNode)) #populate frontier with 'start copy' as only available Node
#while !goal and frontier !empty
while not GOAL_STATE and theFrontier:
stateNode = heapq.heappop(theFrontier)[1] #heappop returns tuple of (weighted-idx, data)
CHECKED_NODES.append(stateNode.xy)
while stateNode.moves and not GOAL_STATE:
EXPANDED_NODES += 1
moveDirection = heapq.heappop(stateNode.moves)[1]
nextNode = Node()
nextNode.setParent(stateNode)
#this makes a call to setHeuristic
nextNode.setLocation((stateNode.xy[0] + moveDirection[0], stateNode.xy[1] + moveDirection[1]))
if nextNode.xy not in CHECKED_NODES and not isInFrontier(nextNode):
if nextNode.checkGoal(): break
nextNode.populateMoves()
heapq.heappush(theFrontier, (nextNode.heuristic,nextNode))
那么现在我们来谈谈这个问题。虽然 A* 找到了最佳路径,但这样做的代价相当高。为了找到 cost:68 的最佳路径,它扩展(导航和搜索)452 个节点以实现此目的。
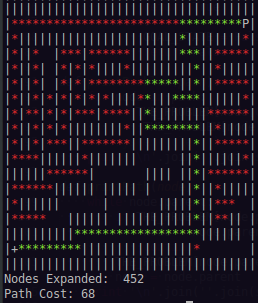
虽然我在 Greedy Best 实现中仅在 160 次扩展中找到了次优路径(成本:74)。
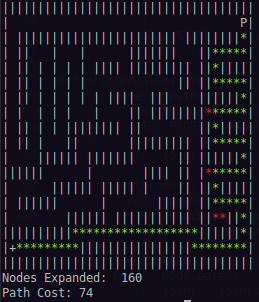
我真的想弄清楚我哪里出了问题。我意识到 Greedy Best First 算法可以自然地表现得像这样,但节点扩展中的差距是如此之大,我觉得这里有些地方是错误的。必须。任何帮助将不胜感激。如果我上面粘贴的内容在某些方面不清楚,我很乐意添加详细信息。
最佳答案
A* 提供问题的最佳答案,贪心最佳优先搜索提供任何解决方案。
预计 A* 必须做更多的工作。
如果您想要 A* 的变体不再是最优的,但可以更快地返回解决方案,您可以查看加权 A*。它只是为启发式算法赋予权重(权重 > 1)。在实践中,它会给你带来巨大的性能提升
例如,你能试试这个吗:
return 2*(abs(goalNodeXY[1] - self.xy[1]) + abs(goalNodeXY[0] - self.xy[0])) + self.costFromStart
关于python - 了解单目标迷宫的 A* 启发式算法,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/28666629/