我有不同类型的发票文件,我想在每个发票文件中查找表格。在这个表中的位置不是恒定的。所以我去图像处理。首先我尝试将发票转换为图像,然后根据表格边框找到轮廓,最后我可以捕捉表格位置。 对于我在下面的代码中使用的任务。
with Image(page) as page_image:
page_image.alpha_channel = False #eliminates transperancy
img_buffer=np.asarray(bytearray(page_image.make_blob()), dtype=np.uint8)
img = cv2.imdecode(img_buffer, cv2.IMREAD_UNCHANGED)
ret, thresh = cv2.threshold(img, 127, 255, 0)
im2, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
margin=[]
for contour in contours:
# get rectangle bounding contour
[x, y, w, h] = cv2.boundingRect(contour)
# Don't plot small false positives that aren't text
if (w >thresh1 and h> thresh2):
margin.append([x, y, x + w, y + h])
#data cleanup on margin to extract required position values.
在这段代码中thresh1,thresh2我会根据文件更新。
因此,使用此代码我可以成功读取图像中表格的位置,使用此位置我将处理我的发票 pdf 文件。例如
样本 1:

示例 2:

示例 3:

输出:
样本 1:

示例 2:

示例 3:

但是,现在我有了一种新格式,它没有任何边框,但它是一个表格。如何解决这个问题?因为我的整个操作只依赖于表格的边框。但现在我没有表格边框。我怎样才能做到这一点?我没有任何想法摆脱这个问题。我的问题是,有没有办法根据表结构找到位置?
例如我的问题输入如下所示:

我想找到它的位置,如下所示:

我该如何解决这个问题? 给我一个解决问题的想法真的很感激。
提前致谢。
最佳答案
毗婆婆是对的。您可以尝试不同的形态学变换,以将像素提取或分组为不同的形状、线条等。例如,方法可以如下:
- 从 Dilation 开始,将文本转换为实心点。
- 然后应用 findContours 函数作为下一步查找文本 边界框。
- 拥有文本边界框后,可以应用一些 启发式算法通过它们将文本框聚类成组 坐标。这样你可以找到一组对齐的文本区域 成行和列。
- 然后您可以按 x 和 y 坐标和/或一些坐标应用排序 对组进行分析以尝试查找分组的文本框是否可以 形成一个表格。
我写了一个小样本来说明这个想法。我希望代码是不言自明的。我也在那里发表了一些评论。
import os
import cv2
import imutils
# This only works if there's only one table on a page
# Important parameters:
# - morph_size
# - min_text_height_limit
# - max_text_height_limit
# - cell_threshold
# - min_columns
def pre_process_image(img, save_in_file, morph_size=(8, 8)):
# get rid of the color
pre = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Otsu threshold
pre = cv2.threshold(pre, 250, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# dilate the text to make it solid spot
cpy = pre.copy()
struct = cv2.getStructuringElement(cv2.MORPH_RECT, morph_size)
cpy = cv2.dilate(~cpy, struct, anchor=(-1, -1), iterations=1)
pre = ~cpy
if save_in_file is not None:
cv2.imwrite(save_in_file, pre)
return pre
def find_text_boxes(pre, min_text_height_limit=6, max_text_height_limit=40):
# Looking for the text spots contours
# OpenCV 3
# img, contours, hierarchy = cv2.findContours(pre, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# OpenCV 4
contours, hierarchy = cv2.findContours(pre, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# Getting the texts bounding boxes based on the text size assumptions
boxes = []
for contour in contours:
box = cv2.boundingRect(contour)
h = box[3]
if min_text_height_limit < h < max_text_height_limit:
boxes.append(box)
return boxes
def find_table_in_boxes(boxes, cell_threshold=10, min_columns=2):
rows = {}
cols = {}
# Clustering the bounding boxes by their positions
for box in boxes:
(x, y, w, h) = box
col_key = x // cell_threshold
row_key = y // cell_threshold
cols[row_key] = [box] if col_key not in cols else cols[col_key] + [box]
rows[row_key] = [box] if row_key not in rows else rows[row_key] + [box]
# Filtering out the clusters having less than 2 cols
table_cells = list(filter(lambda r: len(r) >= min_columns, rows.values()))
# Sorting the row cells by x coord
table_cells = [list(sorted(tb)) for tb in table_cells]
# Sorting rows by the y coord
table_cells = list(sorted(table_cells, key=lambda r: r[0][1]))
return table_cells
def build_lines(table_cells):
if table_cells is None or len(table_cells) <= 0:
return [], []
max_last_col_width_row = max(table_cells, key=lambda b: b[-1][2])
max_x = max_last_col_width_row[-1][0] + max_last_col_width_row[-1][2]
max_last_row_height_box = max(table_cells[-1], key=lambda b: b[3])
max_y = max_last_row_height_box[1] + max_last_row_height_box[3]
hor_lines = []
ver_lines = []
for box in table_cells:
x = box[0][0]
y = box[0][1]
hor_lines.append((x, y, max_x, y))
for box in table_cells[0]:
x = box[0]
y = box[1]
ver_lines.append((x, y, x, max_y))
(x, y, w, h) = table_cells[0][-1]
ver_lines.append((max_x, y, max_x, max_y))
(x, y, w, h) = table_cells[0][0]
hor_lines.append((x, max_y, max_x, max_y))
return hor_lines, ver_lines
if __name__ == "__main__":
in_file = os.path.join("data", "page.jpg")
pre_file = os.path.join("data", "pre.png")
out_file = os.path.join("data", "out.png")
img = cv2.imread(os.path.join(in_file))
pre_processed = pre_process_image(img, pre_file)
text_boxes = find_text_boxes(pre_processed)
cells = find_table_in_boxes(text_boxes)
hor_lines, ver_lines = build_lines(cells)
# Visualize the result
vis = img.copy()
# for box in text_boxes:
# (x, y, w, h) = box
# cv2.rectangle(vis, (x, y), (x + w - 2, y + h - 2), (0, 255, 0), 1)
for line in hor_lines:
[x1, y1, x2, y2] = line
cv2.line(vis, (x1, y1), (x2, y2), (0, 0, 255), 1)
for line in ver_lines:
[x1, y1, x2, y2] = line
cv2.line(vis, (x1, y1), (x2, y2), (0, 0, 255), 1)
cv2.imwrite(out_file, vis)
我有以下输出:
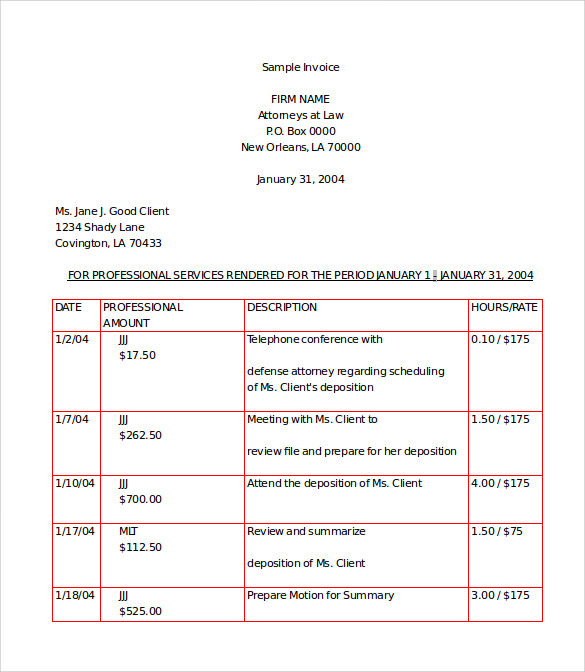
当然,为了使算法更健壮,适用于各种不同的输入图像,它必须进行相应的调整。
更新:针对 findContours 的 OpenCV API 更改更新了代码。如果您安装了旧版本的 OpenCV - 请使用相应的调用。 Related post .
关于python - 如何在图像中找到类似结构的表格,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/50829874/