我正在寻找一种在矩阵行和列上分别执行聚类的方法,重新排序矩阵中的数据以反射(reflect)聚类并将它们放在一起。聚类问题很容易解决,树状图的创建也很容易解决(例如在 this blog 或 "Programming collective intelligence" 中)。但是,我仍然不清楚如何重新排序数据。
最终,我正在寻找一种使用朴素 Python(使用任何“标准”库,例如 numpy、matplotlib 等,但没有 using R 或其他外部工具)创建类似于以下图表的方法。

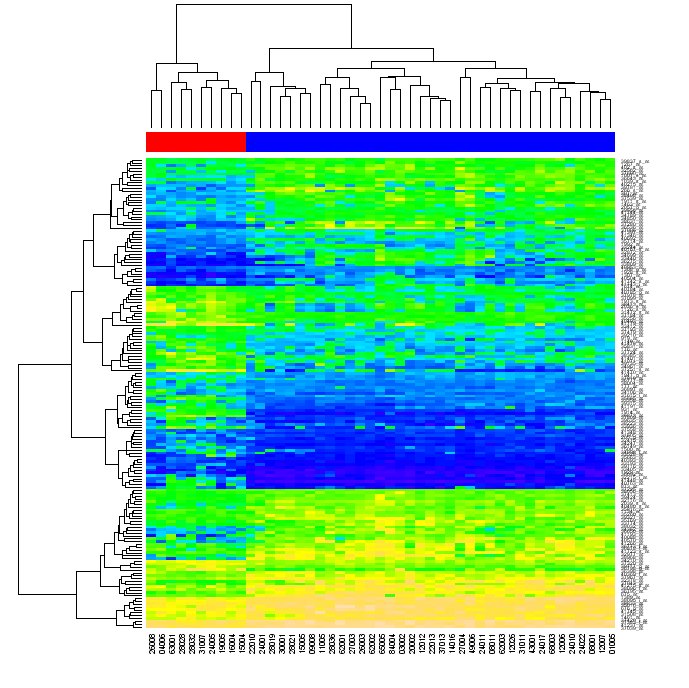
(来源:warwick.ac.uk)
{kind=link}
澄清
有人问我重新排序是什么意思。当您首先按矩阵行,然后按其列对矩阵中的数据进行聚类时,可以通过两个树状图中的位置来识别每个矩阵单元。如果您对原始矩阵的行和列重新排序,使得树状图中彼此接近的元素在矩阵中彼此接近,然后生成热图,则数据的聚类可能对查看者来说变得明显(如上图)
最佳答案
我不确定是否完全理解,但您似乎正在尝试根据各种树状图索引重新索引数组的每个轴。我想这是假设在每个分支描述中都有一些比较逻辑。如果是这种情况,那么这会起作用吗(?):
>>> x_idxs = [(0,1,0,0),(0,1,1,1),(0,1,1),(0,0,1),(1,1,1,1),(0,0,0,0)]
>>> y_idxs = [(1,1),(0,1),(1,0),(0,0)]
>>> a = np.random.random((len(x_idxs),len(y_idxs)))
>>> x_idxs2, xi = zip(*sorted(zip(x_idxs,range(len(x_idxs)))))
>>> y_idxs2, yi = zip(*sorted(zip(y_idxs,range(len(y_idxs)))))
>>> a2 = a[xi,:][:,yi]
x_idxs 和 y_idxs 是树状图索引。 a 是未排序的矩阵。 xi 和 yi 是您的新行/列数组索引。 a2 是排序矩阵,而 x_idxs2 和 y_idxs2 是新的排序树状图索引。这假设在创建树状图时,0 分支列/行总是相对大于/小于 1 分支。
如果您的 y_idxs 和 x_idxs 不是列表而是 numpy 数组,那么您可以以类似的方式使用 np.argsort。
关于python - 重新排序矩阵元素以反射(reflect)朴素python中的列和行聚类,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/2455761/