我正在将一个非常大的数据集导入 SPSS。数据集中的许多字段包含“999”值,表示缺少值。我想指示 SPSS 如此看待它们。但是,SPSS 中的每个变量默认设置为“无缺失值”。在变量 View 中,您必须将“999”定义为每个变量的“离散缺失值”。尽管有数百个变量,但这是一项艰巨的工作:
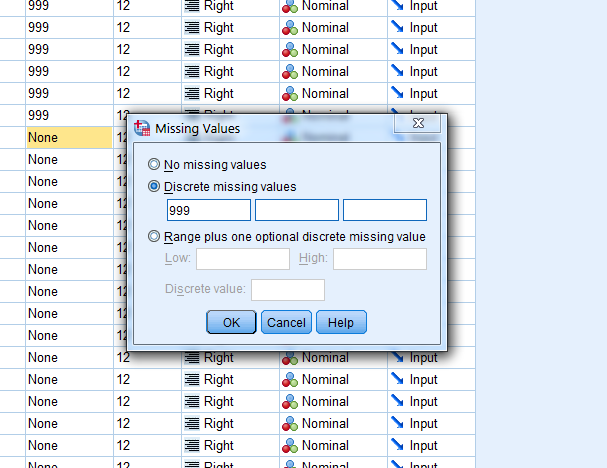
因此:有没有办法将“离散缺失值 999”定义为导入时每个变量的默认缺失值?这会节省我很多工作,但我无法在网上找到答案(我只获得有关如何单独将 999 定义为每个变量的缺失值的教程,就像我现在所做的那样)。
非常感谢您的帮助!
编辑现在我想了一下:我可以轻松地将数据集中的每个“999”替换为空单元格。 SPSS 不会将空单元格视为缺失值吗?
最佳答案
语法是您的 friend ,正如 MISSING VALUES 命令所指出的那样。但您可能有许多变量相同的其他元数据,例如值标签或测量级别。您可以在多个命令的语法中设置这些内容,但您可能需要研究 APPLY DICTIONARY 命令(菜单中的数据 > 复制数据属性)。使用它,您可以设置一个包含所有要共享的元数据的变量,然后将所有这些规范应用于一堆其他变量。
关于spss - 如何将 "999"设置为 SPSS/PASW 中的默认缺失值?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/15908482/