假设我的 data.table 看起来像这样:
dt <- data.table(
a = c( "A", "B", "C", "C" ),
b = c( "U", "V", "W", "X" ),
c = c( 0.1, 0.2, 0.3, 0.4 ),
min = c( 0, 1, 2, 3 ),
max = c( 11, 12, 13, 14 ),
val = c( 100, 200, 300, 400 ),
key = "a"
)
我的实际 data.table 有更多的列和多达几百万行。大约 10% 的行有重复的键 a。我想将这些行与如下所示的函数聚合:
comb <- function( x ){
k <- which.max( x[ ,c ] )
list( b = x[ k, b ], c = x[ k, c ], min = min( x[ , min ] ), max = max( x[ , max ] ), val = sum( x[ ,val ] ) )
}
但是,调用
dt <- dt[ , comb(.SD), by = a ]
非常慢,我想知道如何改进它。如有任何帮助,我们将不胜感激。
最佳答案
通过将 c 放入 key 中并使用 .N 来获取我们可以避免 which.max 的最大值(未经测试):
setkey(dt, a, c)
dt[, c(.SD[.N], min = min[1], val = sum(val)), by = a][, -c(4, 6)]
添加:或此变体:
dt[, c(.SD[.N, c(1:2, 4)], min = min[1], val = sum(val)), by = a]
添加2:我们只使用了.SD,因为您表示您有很多列,但如果您愿意将它们写出来,那么上面的内容可以写成:
dt[, list(b = b[.N], c = c[.N], min = min[1], max = max[.N], val = sum(val)), by = a]
添加 3:又一个变体:
dt[, c("min", "val") := list(min[1], sum(val)), by = a][, .SD[.N], by = a]
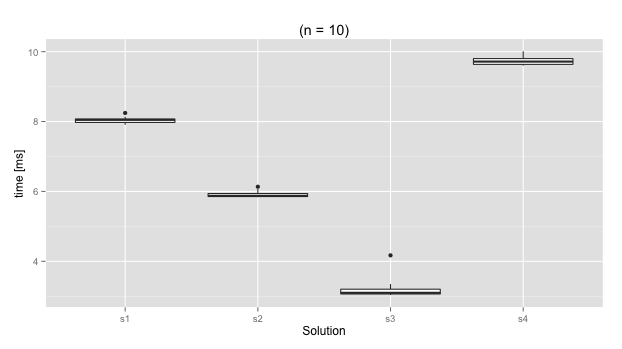
基准
对四种解决方案进行微基准测试得出以下箱线图 (n = 10):
关于r - 改进 data.table 的聚合,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/16770328/