我们有一个带有 3 节点 Cassandra 2.0.6 环的系统。随着时间的推移,该系统上的应用程序负载不断增加,直到达到环无法再处理的极限,从而导致典型的节点过载故障。
我们将环的大小增加了一倍,最近甚至还添加了一个节点,以尝试处理负载,但仍然只有 3 个节点承担所有负载;但不是初始环的原始3个节点。
我们执行了 adding nodes guide 中描述的 bootstrap + cleanup 过程。 。在没有看到环负载有太大改善后,我们还尝试对每个节点进行修复。我们的负载是该系统上 99.99% 的写入。
下面是说明该问题的集群负载图表:
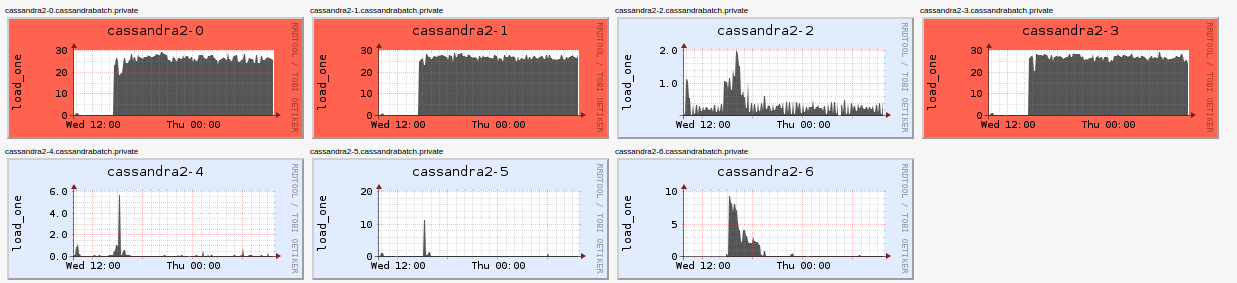
负载最高的表在分区键上具有较高的基数,我希望它能很好地分布在虚拟节点上。
编辑:nodetool信息
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID Rack
UN x.y.z.92 56.83 GB 256 13.8% x-y-z-b53e8ab55e0a rack1
UN x.y.z.253 136.87 GB 256 15.2% x-y-z-bd3cf08449c8 rack1
UN x.y.z.70 69.84 GB 256 14.2% x-y-z-39e63dd017cd rack1
UN x.y.z.251 74.03 GB 256 14.4% x-y-z-36a6c8e4a8e8 rack1
UN x.y.z.240 51.77 GB 256 13.0% x-y-z-ea239f65794d rack1
UN x.y.z.189 128.49 GB 256 14.3% x-y-z-7c36c93e0022 rack1
UN x.y.z.99 53.65 GB 256 15.2% x-y-z-746477dc5db9 rack1
编辑:tpstats(节点高负载)
Pool Name Active Pending Completed Blocked All time blocked
ReadStage 0 0 11591287 0 0
RequestResponseStage 0 0 283211224 0 0
MutationStage 32 405875 349531549 0 0
ReadRepairStage 0 0 3591 0 0
ReplicateOnWriteStage 0 0 0 0 0
GossipStage 0 0 3246983 0 0
AntiEntropyStage 0 0 72055 0 0
MigrationStage 0 0 133 0 0
MemoryMeter 0 0 205 0 0
MemtablePostFlusher 0 0 94915 0 0
FlushWriter 0 0 12521 0 0
MiscStage 0 0 34680 0 0
PendingRangeCalculator 0 0 14 0 0
commitlog_archiver 0 0 0 0 0
AntiEntropySessions 1 1 1 0 0
InternalResponseStage 0 0 30 0 0
HintedHandoff 0 0 1957 0 0
Message type Dropped
RANGE_SLICE 0
READ_REPAIR 196
PAGED_RANGE 0
BINARY 0
READ 0
MUTATION 31663792
_TRACE 24409
REQUEST_RESPONSE 4
COUNTER_MUTATION 0
如何进一步解决此问题?
最佳答案
您需要在属于环的先前节点上运行nodetool cleanup。 Nodetool cleanup 将删除节点当前不拥有的分区键。
似乎添加节点后,键尚未删除,因此导致之前节点的负载更高。
尝试运行
nodetool cleanup
on the previous nodes
关于performance - 使用 Vnode 重新平衡 Cassandra 环,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/28341218/