我正在 Databrick 的云中运行 Spark 1.4。我将一个文件加载到我的 S3 实例中并安装它。安装成功了。但我在创建 RDD 时遇到问题:
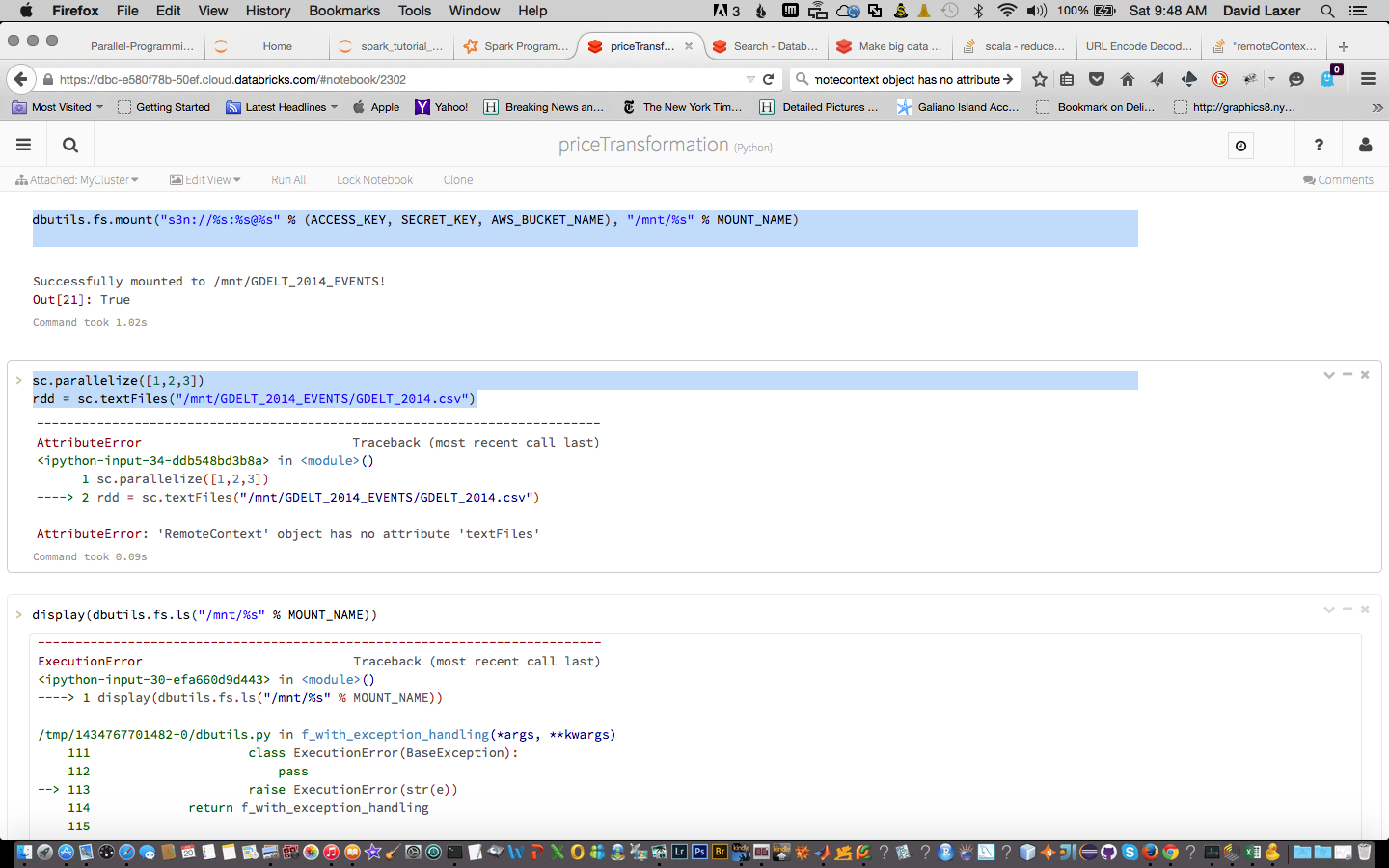
dbutils.fs.mount("s3n://%s:%s@%s" % (ACCESS_KEY, SECRET_KEY, AWS_BUCKET_NAME), "/mnt/%s" % MOUNT_NAME)
有什么想法吗?
sc.parallelize([1,2,3])
rdd = sc.textFiles("/mnt/GDELT_2014_EVENTS/GDELT_2014.csv")
最佳答案
您已经将数据安装到 dbfs 中,这非常棒,而且看起来您只是有一个小拼写错误。我怀疑您想使用 sc.textFile 而不是 sc.textFiles。祝您在 Spark 的冒险之旅中好运。
关于amazon-s3 - "remoteContext object has no attribute",我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/30956598/