在我们当前的系统中,我们将过去作为单个整体应用程序的多个服务分割为独立的服务。
我们在分析方面有一个非常标准的架构(类似于 lambda):
- 解析 HTTP 请求并将其推送到流的前端服务。
- 一种消费者服务,为每种事件构建汇总并直接调用数据库(主要是出于性能原因)。
- 一种报告服务,可读取每个汇总表并返回有意义的数据
- 一种数据管理服务,每 N 小时运行一次批处理作业,读取数据并对其进行采样,删除无用的行和短期数据/报告等。
架构如下图所示:
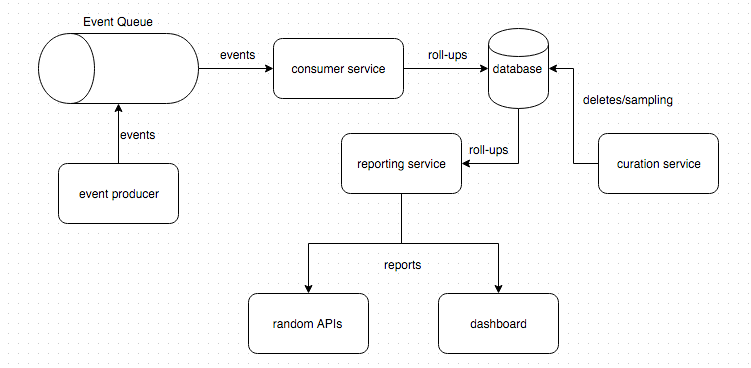
由于消费者和报告服务使用相同的表,我们打破了有界上下文,并且我们在这里遵循反模式,因为每次我们需要进行架构更改时,我们都需要部署消费者(服务创建数据的服务)和报告(读取数据的服务)同时进行。然后我们可能还必须部署管理服务。
我能够提出遵循有界上下文规则的唯一方法是在报告服务上公开一个方法,以根据消费者调用参数构建汇总。策展服务也是如此,公开报告服务中的策展方法。将这种“报告服务”转变为某种上帝服务。
该解决方案的巨大缺点是无法预测报告的延迟,因为同一个盒子可能会执行批处理作业、创建大量汇总并计算报告,因为该服务将承担多种职责。
有没有一种方法可以将这三种服务(消费者、报告、管理)构建为松散耦合,并且不直接依赖于它们之间的数据库集成?
最佳答案
Is there a way to architect this three services (consumer, reporting, curation) to be loosely coupled and don't depend directly on the database integration between them?
不要将数据库公开给消费者、报告和管理服务,而是公开新服务的 API(例如 REST API),该新服务将独占访问数据库。使这些服务不依赖于数据库,而是依赖于此 API,并向消费者、报告和管理服务隐藏数据库。
如果您有大量有界上下文,那么您可以为每个有界上下文创建单独的服务:
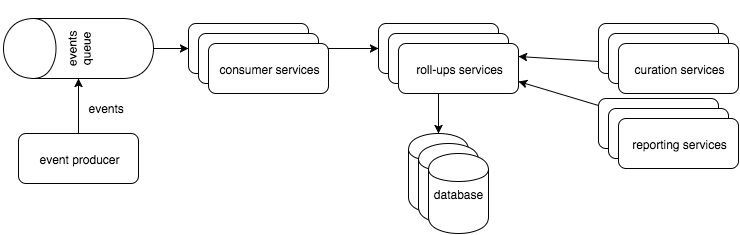
关于architecture - 分布式分析中的微服务有界上下文,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/34450732/