我正在尝试使用 R 中的 NLS 来评估不同群体是否达到不同的渐近线。这里我有两个数据帧 df1 只有一个群体(由站点表示)
df1<- structure(list(Site = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L), .Label = c("ALT01",
"ALT02", "ALT03", "Cotton", "Deep", "Eckhardt", "Green", "Johnson",
"Kissinger", "Marsh", "Sand", "Shypoke", "Sora", "Spike", "Tamora",
"WRP01", "WRP05", "WRP08", "WRP10", "WRP11", "WRP12", "WRP14",
"WRP15", "WRP18"), class = "factor"), Nets = 1:18, Cumulative.spp = c(12L,
13L, 15L, 17L, 17L, 17L, 17L, 19L, 19L, 19L, 19L, 20L, 22L, 22L,
22L, 22L, 22L, 22L)), .Names = c("Site", "Nets", "Cumulative.spp"
), row.names = c(NA, 18L), class = "data.frame")
并且 df2 具有人口(再次由站点代表)
df2 <- structure(list(Site = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L), .Label = c("ALT01",
"ALT02", "ALT03", "Cotton", "Deep", "Eckhardt", "Green", "Johnson",
"Kissinger", "Marsh", "Sand", "Shypoke", "Sora", "Spike", "Tamora",
"WRP01", "WRP05", "WRP08", "WRP10", "WRP11", "WRP12", "WRP14",
"WRP15", "WRP18"), class = "factor"), Nets = c(1L, 2L, 3L, 4L,
5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L,
1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L,
15L, 16L, 17L, 18L), Cumulative.spp = c(12L, 13L, 15L, 17L, 17L,
17L, 17L, 19L, 19L, 19L, 19L, 20L, 22L, 22L, 22L, 22L, 22L, 22L,
7L, 10L, 11L, 12L, 13L, 14L, 14L, 14L, 15L, 15L, 16L, 16L, 16L,
16L, 16L, 17L, 17L, 17L)), .Names = c("Site", "Nets", "Cumulative.spp"
), row.names = c(1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L,
12L, 13L, 14L, 15L, 16L, 17L, 18L, 25L, 26L, 27L, 28L, 29L, 30L,
31L, 32L, 33L, 34L, 35L, 36L, 37L, 38L, 39L, 40L, 41L, 42L), class = "data.frame")
当我为一个群体建模时,一切看起来都很棒:
Model1<-nls(Cumulative.spp ~ SSasympOff(Nets, A, lrc, c0), data = df1)
我想做的是看看是否可以将多个群体添加到同一模型并添加站点变量,我已经尝试过:
Model2<-nls(Cumulative.spp ~ SSasympOff(Nets, A, lrc, c0) + Site , data = df2)
还有这个:
Model2<-nls(Cumulative.spp ~ SSasympOff(Nets + Site , A, lrc, c0), data = df2)
但到目前为止还没有运气,任何帮助将不胜感激。
最佳答案
我们假设您想要不同的 Asym两个群体的参数但共同lrc和c0参数。
首先在(1)中我们展示了如何修改问题中的解决方案以获得答案。 (1) 中的大部分代码只是为了获取起始值,但实际的拟合只有一行代码——如果算上我们在单独的一行中定义了公式这一事实,则为两行。
然后在(2)中我们展示了如何使用算法"plinear"来简化(1)。无需获取线性参数的起始值。在(2a)中,我们展示了进一步的简化,它更容易扩展到更多站点,在(2b)中,我们在所有站点都存在的情况下进一步简化(这不是问题中的情况,但可能是实际情况)数据)。
1) 默认算法 我们可以在 nls 中得到起始值通过分别拟合每个总体( fm1 、 fm2 )和一起拟合( fm3 )。最后拟合不同的模型Asym参数(fm4)。
# get starting values
fo <- Cumulative.spp ~ SSasympOff(Nets, A, lrc, c0)
fm1 <- nls(fo, df2, subset = Site == "ALT01")
fm2 <- nls(fo, df2, subset = Site == "ALT03")
fm3 <- nls(fo, df2)
st <- c(A1 = coef(fm1)[["A"]], A2 = coef(fm2)[["A"]], coef(fm3)[c("lrc", "c0")])
# fit
fo4 <- Cumulative.spp ~ SSasympOff(Nets, A1*(Site=="ALT01")+A2*(Site=="ALT03"), lrc, c0)
fm4 <- nls(fo4, data = df2, start = st)
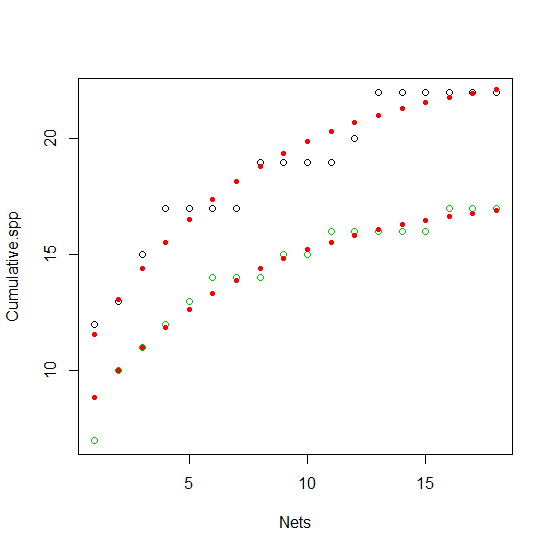
plot(Cumulative.spp ~ Nets, df2, col = Site)
points(fitted(fm4) ~ Nets, df2, col = "red", pch = 20)
2) 线性 实际上 Asym很特殊,因为模型是线性的,我们可以用它来简化上面的过程,因为如果我们切换到 algorithm="plinear" ,我们不需要线性参数的起始值。这样就无需运行 fm1和fm2 。我们只需要fm3生成起始值。请注意"plinear"要求公式的 RHS 是一个矩阵,每一列乘以一个线性参数的系数。这里我们有两个线性参数(每个 Asym 的 Site ),因此它是一个两列矩阵。
# get starting values
fo <- Cumulative.spp ~ SSasympOff(Nets, A, lrc, c0)
fm3 <- nls(fo, df2)
st5 <- coef(fm3)[c("lrc", "c0")]
# fit
mm <- with(df2, cbind(Site=="ALT01", Site=="ALT03"))
fo5 <- Cumulative.spp ~ mm * SSasympOff(Nets,1,lrc,c0)
fm5 <- nls(fo5, data = df2, start = st5, algorithm = "plinear")
2a) mm也可以这样写,其优点是可以扩展到更多站点:
mm <- model.matrix(~ Site - 1, transform(df2, Site = droplevels(Site)))
2b) 如果 Site 的所有级别因素在数据中表示,那么我们可以进一步简化为 droplevels(Site) (这会降低未使用的级别)然后可以简单地 Site允许我们写:
mm <- model.matrix(~ Site - 1, df2)
更新:一些修复和改进。
关于r - 评估 R nls 中多个因素的渐近线,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/41290857/