我是 SPARQL 和图形数据库查询的新手,所以请原谅我的无知,但我正在尝试使用 Fueski 中存储的一些数据编写基本输出,并且正在努力理解处理行重复的最佳实践,因为不同概念之间存在的基数。
我将使用一个简单的例子来证明我的观点。
数据集
这是我当前正在使用的数据和关系类型的代表性示例;
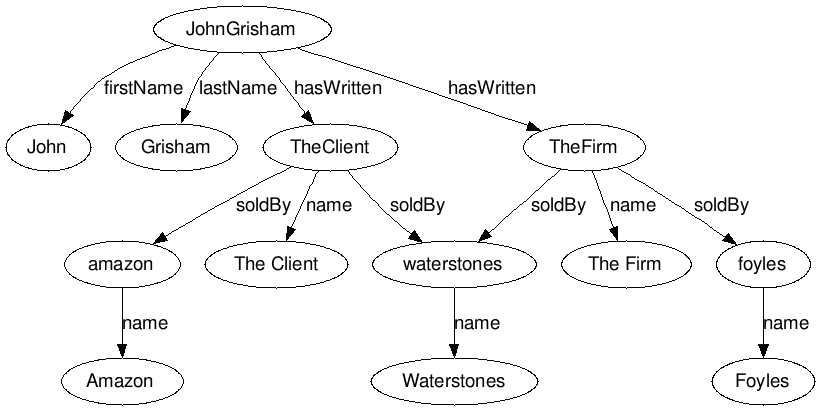{kind=link}
基于这个结构,我生成了以下三元组(N-三元组格式);
<http://www.test.com/ontologies/Author/JohnGrisham> <http://www.test.com/ontologies/property#firstName> "John" .
<http://www.test.com/ontologies/Author/JohnGrisham> <http://www.test.com/ontologies/property#lastName> "Grisham" .
<http://www.test.com/ontologies/Author/JohnGrisham> <http://www.test.com/ontologies/property#hasWritten> <http://www.test.com/ontologies/Book/TheClient> .
<http://www.test.com/ontologies/Author/JohnGrisham> <http://www.test.com/ontologies/property#hasWritten> <http://www.test.com/ontologies/Book/TheFirm> .
<http://www.test.com/ontologies/Book/TheFirm> <http://www.test.com/ontologies/property#name> "The Firm" .
<http://www.test.com/ontologies/Book/TheFirm> <http://www.test.com/ontologies/property#soldBy> <http://www.test.com/ontologies/Retailer/Foyles> .
<http://www.test.com/ontologies/Book/TheFirm> <http://www.test.com/ontologies/property#soldBy> <http://www.test.com/ontologies/Retailer/Waterstones> .
<http://www.test.com/ontologies/Book/TheClient> <http://www.test.com/ontologies/property#name> "The Client" .
<http://www.test.com/ontologies/Book/TheClient> <http://www.test.com/ontologies/property#soldBy> <http://www.test.com/ontologies/Retailer/Amazon> .
<http://www.test.com/ontologies/Book/TheClient> <http://www.test.com/ontologies/property#soldBy> <http://www.test.com/ontologies/Retailer/Waterstones> .
<http://www.test.com/ontologies/Retailer/Amazon> <http://www.test.com/ontologies/property#name> "Amazon" .
<http://www.test.com/ontologies/Retailer/Waterstones> <http://www.test.com/ontologies/property#name> "Waterstones" .
<http://www.test.com/ontologies/Retailer/Foyles> <http://www.test.com/ontologies/property#name> "Foyles" .
渲染输出格式
现在我想做的是渲染一个页面,其中显示所有作者,显示所有书籍以及销售这些书籍的零售商的详细信息。所以像这样(伪代码);
for-each:Author
<h1>Author.firstName + Author.lastName</h1>
for-each:Author.Book
<h2>Book.Name</h2>
Sold By:
for-each:Book.Retailer
<h2>Retailer.name</h2>
SPARQL
为了使渲染正常工作,我的想法是我需要作者的名字和姓氏,然后是他们拥有的所有书籍名称以及这些书籍通过其销售的各种零售商名称,因此我提出了以下 SPARQL;
PREFIX p: <http://www.test.com/ontologies/property#>
SELECT ?authorfirstname
?authorlastname
?bookname
?retailername
WHERE {
?author p:firstName ?authorfirstname;
p:lastName ?authorlastname;
p:hasWritten ?book .
OPTIONAL {
?book p:name ?bookname;
p:soldBy ?retailer .
?retailer p:name ?retailername .
}
}
这提供了以下结果;
{kind=link}
不幸的是,由于行重复,我的基本渲染尝试无法产生预期的输出,事实上,它正在为查询返回的每一行渲染一个新的“作者”部分。
我想我想要理解的是应该如何完成这种类型的渲染。
渲染器是否应该将数据重新组合回它想要遍历的图形形式(老实说,我不明白这是怎么回事)
SPARQL 是否无效 - 有没有办法在 SPARQL 语言本身中实现我想要的功能?
我只是做了一些完全错误的事情吗?
修正案 - 对 GROUP_CONCAT 进行更详细的分析
在查看可用的选项时,我遇到了 GROUP_CONCAT,但经过一番尝试后,我发现它可能不是一个能够给我带来我想要的东西的选项,而且很可能不是。 t 最佳路线。造成这种情况的原因是;
数据大小
虽然我在这篇文章中运行示例的数据集很小,仅涵盖 3 个概念和一个非常有限的数据集,但我在现实世界中运行的实际概念和数据要大得多,连接结果将产生极长的分隔字符串,特别是对于自由格式列,例如描述。
上下文丢失
在尝试 group_concat 时,我很快意识到我无法理解 group_concat 列中的各种数据元素如何相关的上下文。我可以通过使用上面的书籍示例来展示这一点。
SPARQL
PREFIX p: <http://www.test.com/ontologies/property#>
select ?authorfirstname
?authorLastName
(group_concat(distinct ?bookname; separator = ";") as ?booknames)
(group_concat(distinct ?retailername; separator = ";") as ?retailernames)
where {
?author p:firstName ?authorfirstname;
p:lastName ?authorLastName;
p:hasWritten ?book .
OPTIONAL {
?book p:name ?bookname;
p:soldBy ?retailer .
?retailer p:name ?retailername .
}
}
group by ?authorfirstname ?authorLastName
这产生了以下输出;
firstname = "John"
lastname = "Grisham"
booknames = "The Client;The Firm"
retailernames = "Amazon;Waterstones;Foyles"
正如您所看到的,这生成了一个结果行但是您无法再弄清楚各种数据元素之间的关系。哪些零售商销售哪本书?
任何帮助/指导将不胜感激。
当前解决方案
根据下面推荐的解决方案,我使用键的概念将各种数据集整合在一起,但是我稍微调整了一下,以便我对每个概念(例如作者、书籍和零售商)使用查询,然后使用键将结果汇集到我的渲染器中。
结果
firstname lastname books
--------------------------------------------------------------------------------
1 John Grisham ontologies/Book/TheClient|ontologies/Book/TheFirm
图书结果
id name retailers
-------------------------------------------------------------------------------------------------------
1 ontologies/Book/TheClient The Client ontologies/Retailer/WaterStones|ontologies/Retailer/Amazon
2 ontologies/Book/TheFirm The Firm ontologies/Retailer/WaterStones|ontologies/Retailer/Foyles
零售商结果
id name
--------------------------------------------------
1 ontologies/Retailer/Amazon Amazon
2 ontologies/Retailer/Waterstones Waterstones
3 ontologies/Retailer/Foyles Foyles
然后我在渲染器中执行的操作是使用 ID 从各种结果集中提取结果...
for-each author a : authors
output(a.firstname)
for-each book b : a.books.split("|")
book = books.get(b) // get the result for book b (e.g. Id to Foreign key)
output(book.name)
for-each retailer r : book.retailers.split("|")
retailer = retailers.get(r)
output(retailer.name)
如此有效地,您可以从各种不同的结果集中将您想要的内容拼接在一起并呈现出来。
目前看来效果不错。
最佳答案
我发现从代码中的 SPARQL 结果构造对象比尝试形成每个相关资源仅返回一行的查询更容易。
我将使用资源的 URI 来识别哪些行属于哪个资源(在本例中为作者),然后根据所述 URI 合并结果行。
对于 JS 应用程序,我使用代码 here从 SPARQL 结果构造对象。
对于复数,我使用 __在变量名称中表示应从该值构造一个对象。例如,所有带有前缀为 ?book__ 的变量的值将被转换为一个对象,变量名称的其余部分作为对象属性的名称,每个对象由 ?book__id 标识。因此值为 ?book__id和?book__name将产生属性 book对于作者来说,这样 author.book = { id: '<book-uri>', name: 'book name'} (如果有多本书,则为此类对象的列表)。
例如,在本例中,我将使用以下查询:
PREFIX p: <http://www.test.com/ontologies/property#>
SELECT ?id ?firstName ?lastName ?book__id ?book__name
?book__retailer
WHERE {
?id p:firstName ?firstName;
p:lastName ?lastName;
p:hasWritten ?book__id .
OPTIONAL {
?book__id p:name ?book__name;
p:soldBy/p:name ?book__retailer .
}
}
在应用程序代码中,我将构造如下所示的 Author 对象(JavaScript 表示法):
[{
id: '<http://www.test.com/ontologies/Author/JohnGrisham>',
firstName: 'John',
lastName: 'Grisham',
book: [
{
id: '<http://www.test.com/ontologies/Book/TheFirm>',
name: 'The Firm',
retailer: ['Amazon', 'Waterstones', 'Foyles']
},
{
id: '<http://www.test.com/ontologies/Book/TheClient>',
name: 'The Client',
retailer: ['Amazon', 'Waterstones', 'Foyles']
}
]
}]
关于SPARQL 多值属性 - 渲染结果,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/42768578/