我尝试从 www1.nseindia.com 下载 24 个月的数据,但在 Chrome 和 Firefox 驱动程序上失败。在所需位置填写所有值后,它只是卡住并且不会单击。网页没有响应...
下面是我尝试执行的代码:
import time
from selenium import webdriver
from selenium.webdriver.support.ui import Select
id_list = ['ACC', 'ADANIENT']
# Chrome
def EOD_data_Chrome():
driver = webdriver.Chrome(executable_path="C:\Py388\Test\chromedriver.exe")
driver.get('https://www1.nseindia.com/products/content/equities/equities/eq_security.htm')
s1= Select(driver.find_element_by_id('dataType'))
s1.select_by_value('priceVolume')
s2= Select(driver.find_element_by_id('series'))
s2.select_by_value('EQ')
s3= Select(driver.find_element_by_id('dateRange'))
s3.select_by_value('24month')
driver.find_element_by_name("symbol").send_keys("ACC")
driver.find_element_by_id("get").click()
time.sleep(9)
s6 = Select(driver.find_element_by_class_name("download-data-link"))
s6.click()
# FireFox(Gecko)
def EOD_data_Gecko():
driver = webdriver.Firefox(executable_path="C:\Py388\Test\geckodriver.exe")
driver.get('https://www1.nseindia.com/products/content/equities/equities/eq_security.htm')
s1= Select(driver.find_element_by_id('dataType'))
s1.select_by_value('priceVolume')
s2= Select(driver.find_element_by_id('series'))
s2.select_by_value('EQ')
s3= Select(driver.find_element_by_id('dateRange'))
s3.select_by_value('24month')
driver.find_element_by_name("symbol").send_keys("ACC")
driver.find_element_by_id("get").click()
time.sleep(9)
s6 = Select(driver.find_element_by_class_name("download-data-link"))
s6.click()
EOD_data_Gecko()
# Change the above final line to "EOD_data_Chrome()" and still it just remains stuck...
请帮助解决该代码中缺少的内容以下载 24 个月的数据...当我在普通浏览器中执行相同的操作时,通过手动点击,成功...
当您在浏览器中手动执行此操作时,您可以更改以下值:
Set first drop down to : Security wise price volume data
"Enter Symbol" : ACC
"Select Series" : EQ
"Period" (radio button: "For Past") : 24 Months
然后点击“获取数据”按钮,大约 3-5 秒后,数据就会加载,然后当您点击“下载 CSV 格式的文件”时,您就可以下载 CSV 文件了
需要使用您知道的任何在 Python 中进行抓取的库的帮助:Selenium、Beautifulsoup、Requests、Scrappy 等...除非它是 python,否则并不重要...
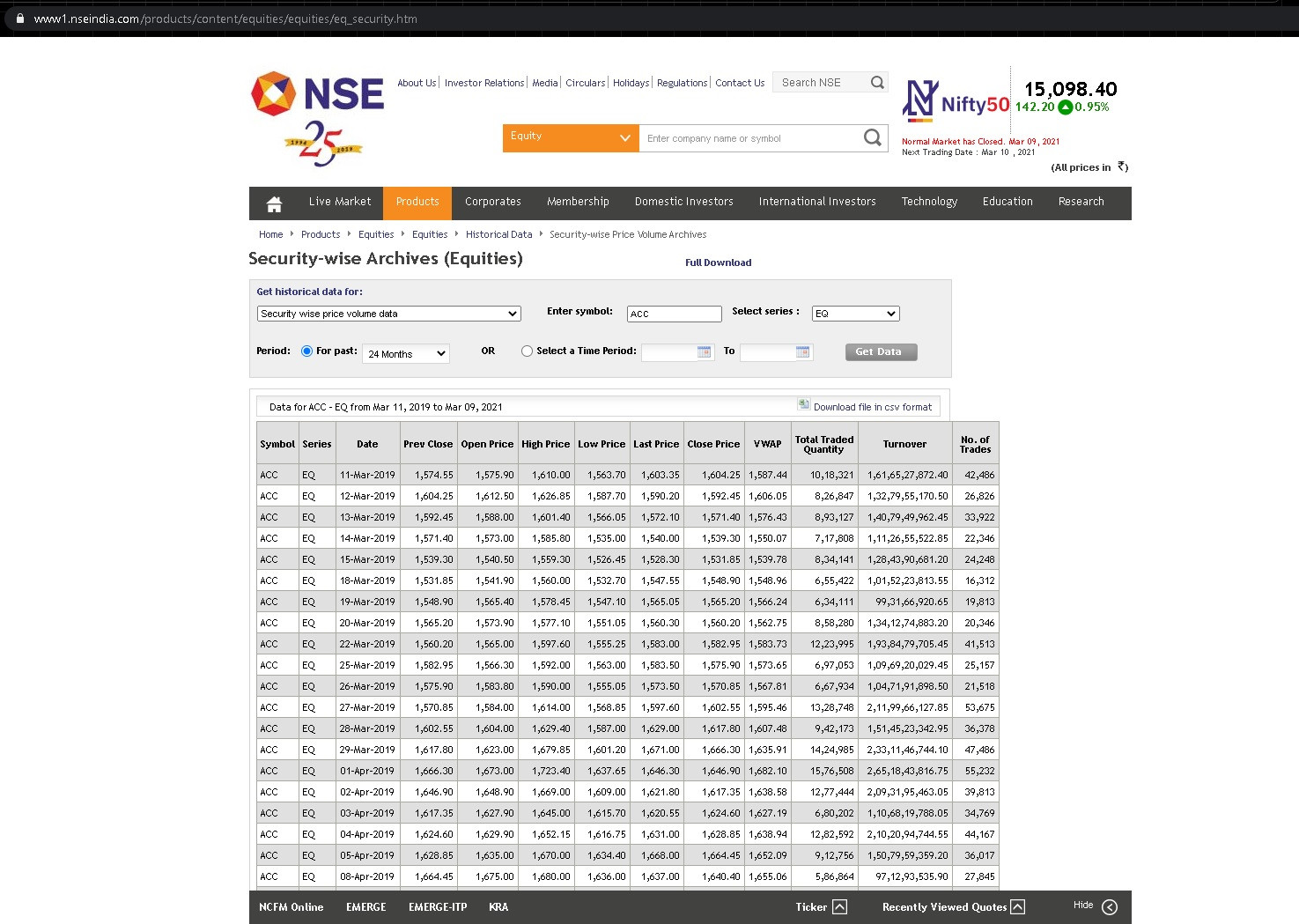
编辑:@Patrick Bormann,请找到屏幕截图...“获取数据”按钮有效。
最佳答案
当你说它手动工作时,你是否尝试过用 Action 链而不是内部点击功能来模拟点击
from selenium.webdriver.common.action_chains import ActionChains
easy_apply = Select(driver.find_element_by_id('dateRange'))
actions = ActionChains(driver)
actions.move_to_element(easy_apply)
actions.click(easy_apply)
actions.perform()
然后你模拟鼠标移动到特定值?
此外,我自己尝试过,当按下“获取数据”按钮时,我没有获取任何数据,因为它似乎有一类“获取”,正如您提到的,但这个按钮不起作用,但正如您所言可以看到存在第二个按钮,称为完整下载,也许你尝试使用这个按钮?因为 GetData 按钮在 Firefox 和 Chrome 上不起作用(当我测试它时)。
您是否已尝试通过链接捕获它? 
更新
当OP在这个紧急问题上寻求帮助时,我提供了一个可行的解决方案。
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
from selenium.webdriver.support.ui import Select
chrome_driver_path = "../chromedriver.exe"
driver = webdriver.Chrome(executable_path=chrome_driver_path)
driver.get('https://www1.nseindia.com/products/content/equities/equities/eq_security.htm')
driver.execute_script("document.body.style.zoom='zoom 25%'")
time.sleep(2)
price_volume = driver.find_element_by_xpath('//*[@id="dataType"]/option[2]').click()
time.sleep(2)
date_range = driver.find_element_by_xpath('//*[@id="dateRange"]/option[8]').click()
time.sleep(2)
series = driver.find_element_by_name('series')
time.sleep(2)
drop = Select(series)
drop.select_by_value("EQ")
time.sleep(2)
driver.find_element_by_name("symbol").send_keys("ACC")
ez_download = driver.find_element_by_xpath('//*[@id="wrapper_btm"]/div[1]/div[3]/a')
actions = ActionChains(driver)
actions.move_to_element(ez_download)
actions.click(ez_download)
actions.perform()
给你,抱歉,花了一点时间,不得不带我儿子去 sleep ......
此解决方案提供以下输出: 我希望它是正确的。如果您想选择其他下拉菜单,您可以更改选择中的字符串(由于索引太多而无法处理的字符串)或 xpath 中的数字,因为数字突出显示索引。该时间通常仅适用于需要时间在网页上构建自身的元素。但我的经验是,太快的变化有时会导致错误。请随意更改时间限制,看看它是否仍然有效。
我希望它是正确的。如果您想选择其他下拉菜单,您可以更改选择中的字符串(由于索引太多而无法处理的字符串)或 xpath 中的数字,因为数字突出显示索引。该时间通常仅适用于需要时间在网页上构建自身的元素。但我的经验是,太快的变化有时会导致错误。请随意更改时间限制,看看它是否仍然有效。
我希望你现在可以继续为你在印度的生活赚点钱。 祝帕特里克一切顺利,
如果您有任何疑问,请随时询问。
更新2
经过一个漫长的夜晚和又一天,我们发现卡住源自该网站,正如该网站所使用的:
Boomerang | Akamai Developer developer.akamai.com/tools/… Boomerangis a JavaScript library forReal User Monitoring (commonly called RUM). Boomerang measures the performance characteristics of real-world page loads and interactions. The documentation on this page is for mPulse’s Boomerang. General API documentation for Boomerang can be found atdocs.soasta.com/boomerang-api/. . What I discovered from the html header.
这显然是一个机器人检测网络/javascript。在这篇SO帖子的帮助下: Can a website detect when you are using Selenium with chromedriver?
我终于解决了这个问题: 我们改变了
chromedriver 中的 var_key 为其他内容,例如:
var key = '$dsjfgsdhfdshfsdiojisdjfdsb_';
此外我将代码更改为:
import time
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import Select
from selenium.webdriver.chrome.options import Options
options = webdriver.ChromeOptions()
chrome_driver_path = "../chromedriver.exe"
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
options.add_argument('--disable-blink-features=AutomationControlled')
driver = webdriver.Chrome(executable_path=chrome_driver_path, options=options)
driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
driver.get('http://www1.nseindia.com/products/content/equities/equities/eq_security.htm')
driver.execute_script("document.body.style.zoom='zoom 25%'")
time.sleep(5)
price_volume = driver.find_element_by_xpath('//*[@id="dataType"]/option[2]').click()
time.sleep(3)
date_range = driver.find_element_by_xpath('//*[@id="dateRange"]/option[8]').click()
time.sleep(5)
series = driver.find_element_by_name('series')
time.sleep(3)
drop = Select(series)
drop.select_by_value("EQ")
time.sleep(4)
driver.find_element_by_name("symbol").send_keys("ACC")
actions = ActionChains(driver)
ez_download = driver.find_element_by_xpath('/html/body/div[2]/div[3]/div[2]/div[1]/div[3]/div/div[1]/form/div[2]/div[3]/p/img')
actions.move_to_element(ez_download)
actions.click(ez_download)
actions.perform()
#' essential because the button has to be loaded
time.sleep(5)
driver.find_element_by_class_name('download-data-link').click()
代码终于工作了,OP很高兴。
关于selenium-webdriver - Python Selenium 获取数据失败,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/66365223/