我正在做一些网页抓取,以从 html 导出文本信息,并使用 NER (Spacy) 来识别诸如管理下的 Assets 、地址和公司成立日期等信息。提取信息后,我想将其放入数据框中。
我正在使用以下脚本:
from bs4 import BeautifulSoup
import numpy as np
from time import sleep
from random import randint
from selenium import webdriver
import pandas as pd
import spacy
from spacy import displacy
import en_core_web_sm
import requests
import re
NER = spacy.load("en_core_web_sm")
url = "https://www.baincapital.com/"
driver = webdriver.Chrome("C:/Program Files/chromedriver.exe")
driver.get(url)
sleep(randint(5,15))
soup = BeautifulSoup(driver.page_source, 'html.parser')
body=soup.body.text
body
body= body.replace('\n', ' ')
body= body.replace('\t', ' ')
body= body.replace('\r', ' ')
body= body.replace('\xa0', ' ')
text3= NER(body)
displacy.render(text3,style="ent",jupyter=True)
输出显示为:
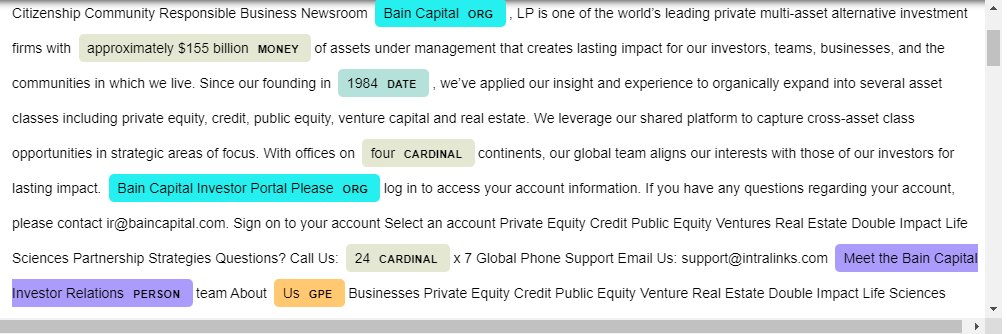
我想将它放在下面的基本表格中:
<表类=“s-表”>
<标题>
实体
已识别
<正文>
钱
1550 亿美元
日期
1984
组织
贝恩资本
组织
请贝恩资本投资者门户
红衣主教
四
红衣主教
24
GPE
美国
本质上,获取突出显示的信息并将其放置在具有识别特征的数据框中。
最佳答案
获得纯文本的 body 后,您可以将文本解析为文档并获取所有实体及其标签和文本的列表,然后使用这些数据实例化 Pandas 数据框:
#... your code here ...
body=soup.body.text
# now, this is the modification:
body = ' '.join(body.split())
doc = NER(body)
entities = [(e.label_,e.text) for e in doc.ents]
df = pd.DataFrame(entities, columns=['Entity','Identified'])
请注意,body = ' '.join(body.split()) 行用于以比您使用的更简单、更短的方式标准化所有空白。
关于python - 在数据框中显示 NER Spacy 数据,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/70855135/