我希望能够使用 dplyr 来平均行,其中任何 n 或更多数字列中存在相同的值,并且 一个列。
如果:
n <- 3
和
df <- data.frame(a = c("one", "one", "one", "one", "three"),
b = c(1,1,1,2,3),
c = c(2,2,2,7,12),
d = c(6,6,7,8,10),
e = c(1,4,1,3,4))
然后我希望对前三行进行平均(因为它们之间的 4 个数值中有 3 个相同,并且 a 中的值也相同)。我不希望第四行包含在平均值中,因为尽管 a 中的值相同,但它没有相同的数值。
之前:
a b c d e
[1] one 1 2 6 1
[2] one 1 2 6 4
[3] one 1 2 7 1
[4] one 2 7 8 3
[5] four 3 12 10 4
之后:
a b c d e
[1] one 1 2 6.3 2
[2] one 2 7 8 3
[3] four 3 12 10 4
我的数据框在现实生活中要大得多,并且包含大量其他列。
编辑:
[1] 行和 [2] 行有 3 个相同的值(在 b、c 和 列中d。行 [1] 和 [3] 有 3 个相同的值(在列 b、c 和 e。这就是为什么我希望对它们进行平均。
最佳答案
在这里,我首先按 a 列对数据框进行分组。然后,对于每个子数据帧,我根据行之间不同元素的数量计算距离矩阵。
使用包 proxy 是因为它可以轻松计算自定义距离。
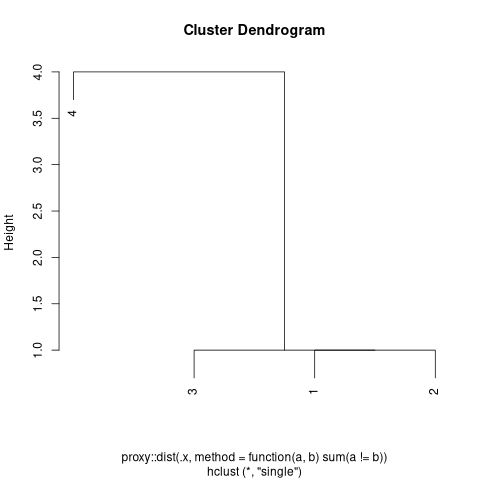
然后,我执行单链接聚类,并在略高于 1 的高度处砍伐树。这将确保聚类中的每个成员至少有 (4 - 1) = 3 元素与同一集群的至少另一个成员相同。
最后,我通过簇号gid总结每个子数据帧。
library(dplyr)
library(tidyr)
library(proxy)
n <- 3
df <- data.frame(a = c("one", "one", "one", "one", "three"),
b = c(1,1,1,2,3),
c = c(2,2,2,7,12),
d = c(6,6,7,8,10),
e = c(1,4,1,3,4))
df |>
group_by(a) |>
group_modify(~{
gid <- if(nrow(.x) > 1)
proxy::dist(.x, method = \(a,b) sum(a != b)) |>
hclust(method="single") |>
cutree(h = 0.1 + ncol(.x) - n)
else
1
group_by(cbind(.x, gid), gid) |>
summarize(across(everything(), mean))
})
# A tibble: 3 × 6
# Groups: a [2]
a gid b c d e
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 one 1 1 2 6.33 2
2 one 2 2 7 8 3
3 three 1 3 12 10 4
以下是从前 4 行获得的树状图示例:
关于r - 超过 n 个数字列中具有重复值的数据帧的平均行数,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/71250874/