我正在尝试将类似于 R 的 tidyr::spread 的东西应用于我的 pandas 数据帧。我在某些地方看到人们使用 pd.pivot 但到目前为止我没有成功。
因此,在这个示例中,我有以下数据框 DF:
df = pd.DataFrame({'action_id' : [1,2,1,4,5],
'name': ['jess', 'alex', 'jess', 'cath', 'mary'],
'address': ['house', 'house', 'park', 'park', 'park'],
'date': [ '01/01', '02/01', '03/01', '04/01', '05/01']})
它看起来怎么样:
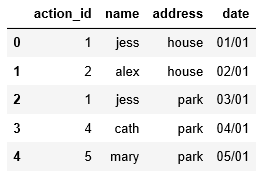
好吧,所以我想要的是一个以“action_id”和“name”作为索引的多索引数据透视表,“传播”地址列并用“日期”列填充它。所以我的 df 看起来像这样:

我尝试做的是:
df.pivot(index = ['action_id', 'name'], columns = 'address', values = 'date')
我收到错误TypeError:MultiIndex.name必须是可散列类型
有人知道我做错了什么吗?
最佳答案
您不需要在pd.pivot中提及索引
这会起作用
import pandas as pd
df = pd.DataFrame({'action_id' : [1,2,1,4,5],
'name': ['jess', 'alex', 'jess', 'cath', 'mary'],
'address': ['house', 'house', 'park', 'park', 'park'],
'date': [ '01/01', '02/01', '03/01', '04/01', '05/01']})
df = pd.concat([df, pd.pivot(data=df, index=None, columns='address', values='date')], axis=1) \
.reset_index(drop=True).drop(['address','date'], axis=1)
print(df)
action_id name house park
0 1 jess 01/01 NaN
1 2 alex 02/01 NaN
2 1 jess NaN 03/01
3 4 cath NaN 04/01
4 5 mary NaN 05/01
要达到你想要的效果,你需要进行分组
df = df.groupby(['action_id','name']).agg({'house':'first','park':'first'}).reset_index()
print(df)
action_id name house park
0 1 jess 01/01 03/01
1 2 alex 02/01 NaN
2 4 cath NaN 04/01
3 5 mary NaN 05/01
如果答案对您有帮助,别忘了采纳
关于python - 错误 pd.pivot "MultiIndex.name must be a hashable type",我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/61086310/