我的坐标数据(x 坐标和 y 坐标)在以下范围内: Xpos:27-1367nm,Ypos:67-1014nm。一个数据集由大约 2500-3500 个数据点组成。 这是此类数据集的标题:
XPos YPos
1 29 211
2 31 609
3 33 1001
4 35 508
5 37 424
6 39 584
7 40 378
8 41 204
9 41 444
10 41 872
...
[![绘制的数据][1]][1]
现在我想通过将由相同大小的象限组成的网格应用于 R 中的数据来索引数据点。结果应该是一个新列“grid_index”,其中包含数据点所在的唯一象限_ID(请参阅图像)。是否有捷径可寻?我想尝试不同的网格单元大小来分区数据,例如象限大小为 50nm、100nm、200nm 或 400nm,矩形大小为 100nm x 200nm 或 50nm x100nm。
[![数据品脱索引网格][2]][2]
[![每个网格象限应该有一个唯一的 ID][3]][3]
如果有任何帮助,我将非常感激。
最佳答案
这是 findInterval 的一种方法:
首先设置一个具有适当数量索引的矩阵:
pos.matrix <- matrix(1:35,byrow = TRUE, nrow = 5)
pos.matrix
[,1] [,2] [,3] [,4] [,5] [,6] [,7]
[1,] 1 2 3 4 5 6 7
[2,] 8 9 10 11 12 13 14
[3,] 15 16 17 18 19 20 21
[4,] 22 23 24 25 26 27 28
[5,] 29 30 31 32 33 34 35
接下来使用findInterval查找其所在矩阵的索引。您可以使用 by = 参数控制网格的大小。请注意,矩阵的维度必须与 findInterval 中提供的间隔数匹配。我们需要使用 abs 因为图表上的 y 值正在减小。
grid <- apply(cbind(findInterval(data[,"XPos"],seq(0,1400,by = 200)),
abs(findInterval(data[,"YPos"],seq(0,1000,by = 200)) - 6)),
MARGIN = 1,
function(x) pos.matrix[x[2],x[1]])
grid[1:25]
[1] 30 34 31 17 19 26 15 31 19 5 18 32 25 25 14 20 22 19 35 2 16 8 29 29 16
plot(NA,xlim = c(0,1400), ylim = c(0,1000), xlab = "XPos", ylab = "YPos", cex.axis = 0.8)
text(data[,1],data[,2], labels = grid, cex = 0.4)
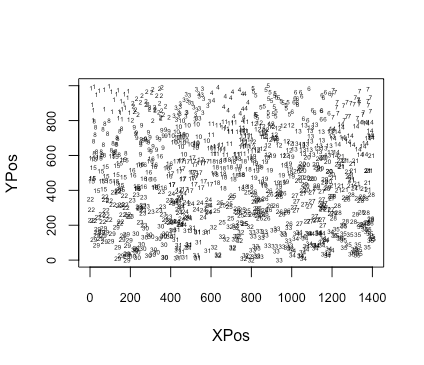
示例数据
set.seed(3)
data <- data.frame(XPos = runif(1000,0,1400), YPos = runif(1000,0,1000))
关于r - 如何在R中根据网格索引坐标数据?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/62155325/