虽然我很欣赏这个问题的数学含量很高,但这个问题的真正答案将对所有正在处理 MongoDB 的 $bucket 的人有所帮助。运算符(或其 SQL 类比),以及构建集群/热图图表数据。
问题的详细描述:
我的数据库中有一组唯一/不同的价格值(它始终是一个 numbers 数组,精度为 0.01)。
正如您所见,它的大部分值都在 ~8 到 40 之间(在本例中)。
[
7.9, 7.98, 7.99, 8.05, 8.15, 8.25, 8.3, 8.34, 8.35, 8.39,
8.4, 8.49, 8.5, 8.66, 8.9, 8.97, 8.98, 8.99, 9, 9.1,
9.15, 9.2, 9.28, 9.3, 9.31, 9.32, 9.4, 9.46, 9.49, 9.5,
9.51, 9.69, 9.7, 9.9, 9.98, 9.99, 10, 10.2, 10.21, 10.22,
10.23, 10.24, 10.25, 10.27, 10.29, 10.49, 10.51, 10.52, 10.53, 10.54,
10.55, 10.77, 10.78, 10.98, 10.99, 11, 11.26, 11.27, 11.47, 11.48,
11.49, 11.79, 11.85, 11.9, 11.99, 12, 12.49, 12.77, 12.8, 12.86,
12.87, 12.88, 12.89, 12.9, 12.98, 13, 13.01, 13.49, 13.77, 13.91,
13.98, 13.99, 14, 14.06, 14.16, 14.18, 14.19, 14.2, 14.5, 14.53,
14.54, 14.55, 14.81, 14.88, 14.9, 14.98, 14.99, 15, 15.28, 15.78,
15.79, 15.8, 15.81, 15.83, 15.84, 15.9, 15.92, 15.93, 15.96, 16,
16.5, 17, 17.57, 17.58, 17.59, 17.6, 17.88, 17.89, 17.9, 17.93,
17.94, 17.97, 17.99, 18, 18.76, 18.77, 18.78, 18.99, 19.29, 19.38,
19.78, 19.9, 19.98, 19.99, 20, 20.15, 20.31, 20.35, 20.38, 20.39,
20.44, 20.45, 20.49, 20.5, 20.69, 20.7, 20.77, 20.78, 20.79, 20.8,
20.9, 20.91, 20.92, 20.93, 20.94, 20.95, 20.96, 20.99, 21, 21.01,
21.75, 21.98, 21.99, 22, 22.45, 22.79, 22.96, 22.97, 22.98, 22.99,
23, 23.49, 23.78, 23.79, 23.8, 23.81, 23.9, 23.94, 23.95, 23.96,
23.97, 23.98, 23.99, 24, 24.49, 24.5, 24.63, 24.79, 24.8, 24.89,
24.9, 24.96, 24.97, 24.98, 24.99, 25, 25.51, 25.55, 25.88, 25.89,
25.9, 25.96, 25.97, 25.99, 26, 26.99, 27, 27.55, 28, 28.8,
28.89, 28.9, 28.99, 29, 29.09, 30, 31.91, 31.92, 31.93, 33.4,
33.5, 33.6, 34.6, 34.7, 34.79, 34.8, 35, 38.99, 39.57, 39.99,
40, 49, 50, 50.55, 60.89, 99.99, 20000, 63000, 483000
]
问题本身或如何从非正态元素中清除(非)正态分布尾部
我需要在这个数组中找到不相关的值,某种“脏尾”,并将它们删除。实际上,我什至不需要从数组中删除它,真正的情况是找到 latest相关号码。将其定义为cap值,用于查找 floor 之间的范围(最小相关)和 cap (最大相关),例如:
floor value => 8
cap value => 40
我在说什么?
例如,对于上面的数组:它将是 40(甚至可能是 60)之后的所有值,例如 49, 50, 50.55, 60.89, 99.99, 20000, 63000, 483000
他们都被我定义为非正常人。
什么算作答案?
S 级。清晰/优化的代码(语言并不重要,但 JavaScript 是首选)或公式(如果数学有的话)可以在一小段时间/无资源的情况下解决问题。如果我什至不需要检查数组中的每个元素,或者可以跳过其中一些元素,例如从
peak开始,那就完美了/数组中最受欢迎的值。一层。您自己的经验或
code尝试任何相关结果或改进当前公式以获得更好的性能。B 级。有用的东西。博客文章/谷歌链接。主要要求是有意义。欢迎非显而易见的解决方案。即使您的代码格式非常糟糕等等。
TL:DR 视觉清晰度
按照什么标准以及如何“瞄准尾部”/从数组中删除具有 x(急剧上升且很少出现)值的不相关元素?
最佳答案
给定的数据集有一些巨大的异常值,这使得使用标准统计方法进行分析有些困难(如果表现更好,我建议对其拟合几个候选分布并找出最适合的 - 对数正态分布, beta 分布、gamma 分布等)。
确定忽略哪些异常值的问题一般可以通过更简单但不太严格的方法来解决;一种方法是比较不同百分位数的数据值,并丢弃差异变得“太高”的数据(对于适当选择的“太高”值)。
例如,如果我们向上移动两个百分位数,则以下是最后几个条目;增量列给出了前一个百分位数与当前百分位数之间的差异。
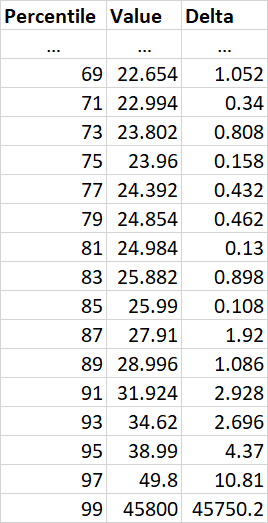
在这里,您可以看到,一旦我们达到 87,与上一个条目的差异几乎增加了 2,并且从那里开始(大部分)上升。为了使用一个“好”的数字,我们将截止值设置为第 85 个百分位数,并忽略高于该值的所有值。
鉴于上面名为 data 的数组中的排序列表,我们忽略上面的任何索引
Math.floor(data.length*85/100)
如果上面的分析应该动态变化(或者提醒注意 85 不是正确值的偏差),则可以在代码中重复上面的分析,但我将其作为练习留给读者。
关于arrays - 从(非)正态分布数字数组中删除不相关的值(尾部),我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/63288743/