我正在尝试使用 python 进行网络抓取,这是一个在巴西非常有名的租赁房屋/公寓网站(5 andar)。
我需要输入每个元素并在其中抓取一些信息。 有关如何做的任何提示?因为它是无限滚动类型的页面?
OBS:现在我已经可以输入每个元素并抓取数据了。我唯一的问题是不断滚动/抓取新数据。
以下是该网站的链接:https://www.quintoandar.com.br/alugar/imovel/sao-paulo-sp-brasil 和它的图片
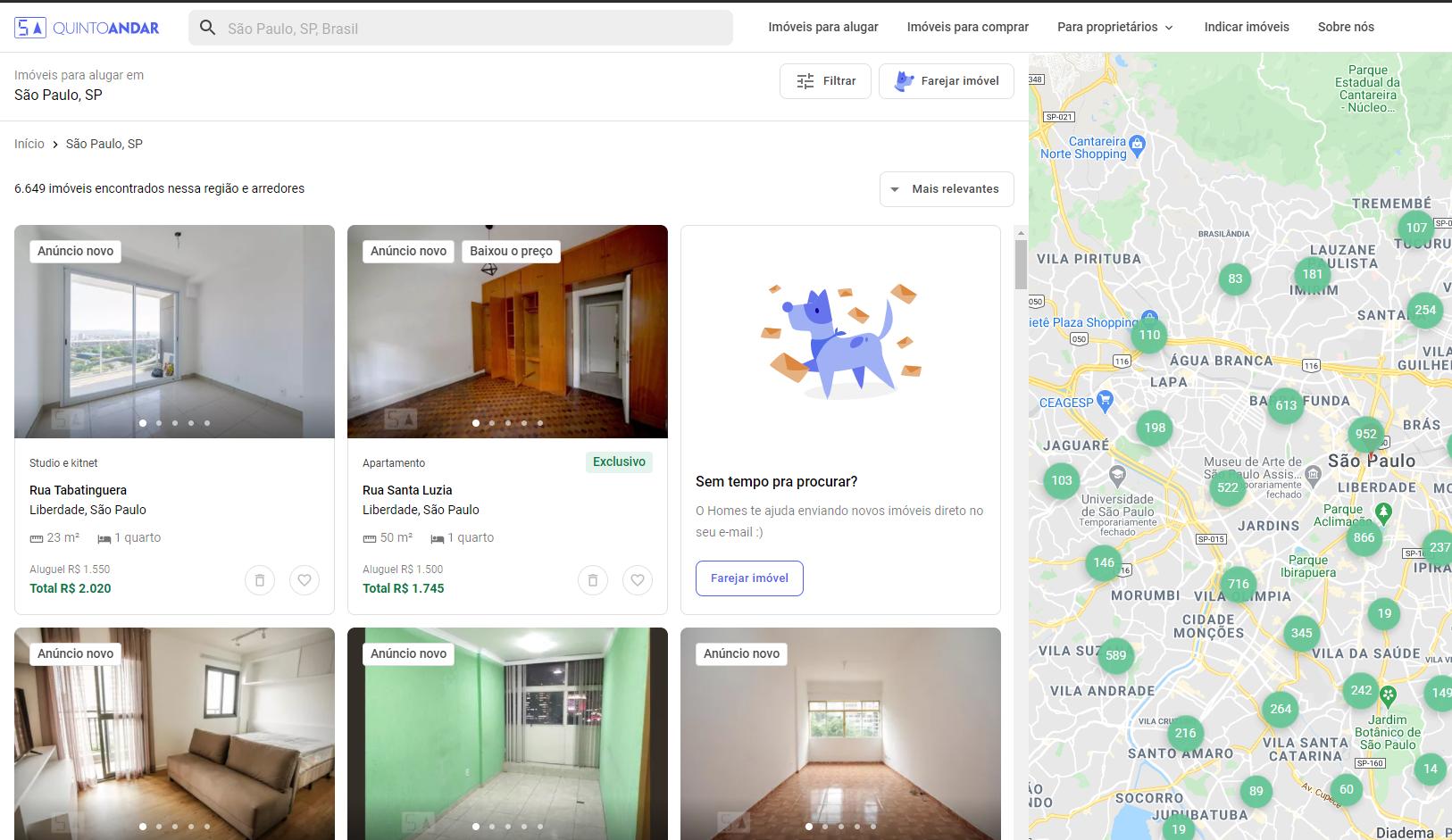
这是我到目前为止所拥有的。它已经在处理第一个项目
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import numpy as np
import pandas as pd
#Initializing the webdriver
options = webdriver.ChromeOptions()
#Change the path to where chromedriver is in your home folder.
path = 'chromedriver'
driver = webdriver.Chrome(executable_path=path, options=options)
driver.set_window_size(1600, 1024)
url = 'https://www.quintoandar.com.br/alugar/imovel/sao-paulo-sp-brasil'
driver.get(url)
time.sleep(5)
num_houses = 40
houses=[]
#Fix (scrolling the page a few items and going back to initial)
aux = driver.find_elements_by_xpath("//div[@class='sc-1qwl1yl-0 igVsBW']")
driver.execute_script("arguments[0].scrollIntoView();", aux[12])
time.sleep(1)
driver.execute_script("arguments[0].scrollIntoView();", aux[0])
time.sleep(1)
house_buttons = driver.find_elements_by_xpath("//div[@class='sc-1qwl1yl-0 igVsBW']")
for house_button in house_buttons:
if (not 'Sem tempo pra procurar' in house_button.text) and (not 'Ainda não encontrou seu lar' in house_button.text):
house_button.click()
#Wait for new tab
time.sleep(2)
#Switch to it
driver.switch_to.window(driver.window_handles[1])
#Wait page load its infos
time.sleep(4)
try:
title = driver.find_element_by_xpath("//h1[@class='sc-1q9n36n-0 ghXeyc sc-bdVaJa hgGleC']").text
address = driver.find_element_by_xpath("//p[@data-testid='listing-address-subtitle']").text
except:
title = address = np.nan
#General Infos
try:
infos = driver.find_elements_by_xpath("//div[@class='MuiGrid-root tptht-0 fAvqys MuiGrid-item MuiGrid-grid-xs-3 MuiGrid-grid-sm-3 MuiGrid-grid-md-1']")
size = infos[0].text
bedroom = infos[1].text
bathroom = infos[2].text
garage = infos[3].text
floor = infos[4].text
pet = infos[5].text
furniture = infos[6].text
subway = infos[7].text
except:
size = bedroom = bathroom = garage = floor = pet = furniture = subway = np.nan
#Price Infos
infos = driver.find_elements_by_xpath("//li[contains(@class, 'MuiListItem-root rf1epz-0')]")
for info in infos:
if 'Aluguel' in info.text: rent = info.text
elif 'Condomínio' in info.text: other = info.text
elif 'IPTU' in info.text: taxes = info.text
elif 'Seguro incêndio' in info.text: insurance = info.text
elif 'Taxa de serviço' in info.text: services = info.text
elif 'Total' in info.text: total = info.text
houses.append({
"Title":title,
"Address":address,
"Size":size,
"Bedroom":bedroom,
"Garage":garage,
"Floor":floor,
"Pet":pet,
"Size":size,
"Subway":subway,
"Rent":rent,
"Other":other,
"Taxes":taxes,
"Insurance":insurance,
"Services":services,
"Total":total
})
#Close Tab and go back to main
driver.close()
driver.switch_to.window(driver.window_handles[0])
time.sleep(.5)
最佳答案
你需要做的是:
- 找到您需要的主页按钮
- 向下滚动到此按钮
- 点击按钮,切换标签页,获取数据,返回主标签页
- 转到步骤 1。
以下是执行此操作的代码(提取数据除外):
from selenium import webdriver
import time
import numpy as np
url = 'https://www.quintoandar.com.br/alugar/imovel/sao-paulo-sp-brasil'
xpath_house_buttons = "//div[@class='sc-1qwl1yl-0 igVsBW']"
x_path_title = "//h1[@class='sc-1q9n36n-0 ghXeyc sc-bdVaJa hgGleC']"
x_path_address = "//p[@data-testid='listing-address-subtitle']"
num_houses = 40
houses = []
def scroll_to_house_button(driver, num_btn) -> bool:
"""
returns true if it could scroll to the house button
"""
try:
house_buttons = driver.find_elements_by_xpath(xpath_house_buttons)
driver.execute_script("arguments[0].scrollIntoView();", house_buttons[num_btn])
return True
except:
return False
def switch_to_house_tab(driver) -> bool:
"""
returns true if switching tab was successful
"""
try:
driver.switch_to.window(driver.window_handles[1])
return True
except:
return False
def switch_to_main_tab(driver) -> bool:
"""
returns true if switching tab was successful
"""
try:
driver.switch_to.window(driver.window_handles[0])
return True
except:
return False
def get_house_button_index(house_buttons, houses_scraped_text, index):
"""
returns house_button's index in house_buttons
"""
# at the beginning, the house to scrape is given by its index
if len(houses_scraped_text) < 5:
return index
# afterwards, we try to find by comparing the buttons' content
else:
for i in reversed(range(len(house_buttons))):
if (house_buttons[i].text == houses_scraped_text[-1]) and (house_buttons[i - 1].text == houses_scraped_text[-2]):
return i + 1
# Initializing the webdriver
driver = webdriver.Chrome()
driver.set_window_size(1600, 1024)
driver.get(url)
# get data
i = 0
houses_scraped_text = []
while len(houses) < num_houses:
house_buttons = driver.find_elements_by_xpath(xpath_house_buttons)
# as house_buttons never exceeds a length of 30,
# we need a smart way of getting the next one
index_btn = get_house_button_index(house_buttons, houses_scraped_text, i)
house_button = house_buttons[index_btn]
houses_scraped_text.append(house_button.text)
# can't scroll to house button => wait 1 sec
while not scroll_to_house_button(driver, num_btn=index_btn):
time.sleep(1)
print("scroll to house -- house", i + 1)
# filter houses to be scraped
if not ((not 'Sem tempo pra procurar' in house_button.text) and (not 'Ainda não encontrou seu lar' in house_button.text)):
print("house filtered -- house", i + 1, "\n")
i += 1 # you have to increment here to not loop over the same house forever
continue
# new house tab not open yet => wait 1 sec
while len(driver.window_handles) != 2: # check number of open tabs
house_button.click()
time.sleep(1)
print("new house tab opened -- house", i + 1)
# can't switch yet => wait 1 sec
while not switch_to_house_tab(driver):
time.sleep(1)
print("switched to new house tab -- house", i + 1)
##################
# LOAD DATA HERE #
##################
print("data loaded -- house", i + 1)
# close tab
driver.close()
# can't switch back to main => wait 1 sec
while not switch_to_main_tab(driver):
time.sleep(1)
print("house tab closed & switched back to main -- house", i + 1)
print(len(houses), "house scraped\n")
i += 1
关于python - 抓取无限滚动页面,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/64527791/