给定一个方阵,我想将每一行移动其行号并对列求和。例如:
array([[0, 1, 2], array([[0, 1, 2],
[3, 4, 5], -> [3, 4, 5], -> array([0, 1+3, 2+4+6, 5+7, 8]) = array([0, 4, 12, 12, 8])
[6, 7, 8]]) [6, 7, 8]])
我有 4 个解决方案 - fast , 慢, slower和 slowest,它们执行完全相同的操作,并按速度排名:
def fast(A):
n = A.shape[0]
retval = np.zeros(2*n-1)
for i in range(n):
retval[i:(i+n)] += A[i, :]
return retval
def slow(A):
n = A.shape[0]
indices = np.arange(n)
indices = indices + indices[:,None]
return np.bincount(indices.ravel(), A.ravel())
def slower(A):
r, _ = A.shape
retval = np.c_[A, np.zeros((r, r), dtype=A.dtype)].ravel()[:-r].reshape(r, -1)
return retval.sum(0)
def slowest(A):
n = A.shape[0]
retval = np.zeros(2*n-1)
indices = np.arange(n)
indices = indices + indices[:,None]
np.add.at(retval, indices, A)
return retval
令人惊讶的是,非矢量化解决方案是最快的。这是我的基准:
A = np.random.randn(1000,1000)
%timeit fast(A)
# 1.85 ms ± 20 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%timeit slow(A)
# 3.28 ms ± 9.55 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit slower(A)
# 4.07 ms ± 18.7 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit slowest(A)
# 58.4 ms ± 993 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
是否存在更快的解决方案?如果不是,有人可以解释为什么实际上 fast 是最快的吗?
编辑
稍微加速慢:
def slow(A):
n = A.shape[0]
indices = np.arange(2*n-1)
indices = np.lib.stride_tricks.as_strided(indices, A.shape, (8,8))
return np.bincount(indices.ravel(), A.ravel())
以与 Pierre 相同的方式绘制运行时(以 2**15 作为上限 - 由于某种原因 slow 无法处理此大小)
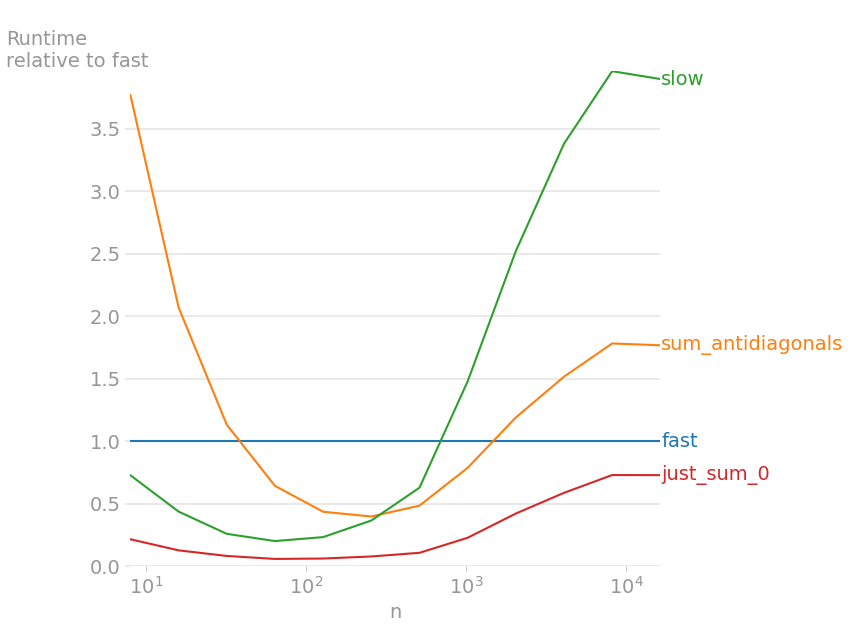
100x100 的数组,slow 比任何解决方案(不使用 numba)都要快一些。 sum_antidiagonals 仍然是 1000x1000 数组的最佳选择。
最佳答案
这是一种有时比您的“fast()”版本更快的方法,但仅限于n的有限范围内(对于 n x n 数组,大约在 30 到 1000 之间。即使使用 numba,循环 (fast()) 在大型数组上也很难被打败,并且实际上渐近收敛到简单的时间a.sum(axis=0),这表明这与大型数组的效率差不多(感谢您的循环!)
该方法(我将其称为 sum_antidiagonals())在 a 的条纹版本上使用 np.add.reduce()以及来自相对较小的一维阵列的化妆掩模,该阵列被 strip 化以创建二维阵列的错觉(不消耗更多内存)。
此外,它不仅限于方阵(但是 fast() 也可以轻松地适应这种概括,请参阅本节底部的 fast_g()帖子)。
def sum_antidiagonals(a):
assert a.flags.c_contiguous
r, c = a.shape
s0, s1 = a.strides
z = np.lib.stride_tricks.as_strided(
a, shape=(r, c+r-1), strides=(s0 - s1, s1), writeable=False)
# mask
kern = np.r_[np.repeat(False, r-1), np.repeat(True, c), np.repeat(False, r-1)]
mask = np.fliplr(np.lib.stride_tricks.as_strided(
kern, shape=(r, c+r-1), strides=(1, 1), writeable=False))
return np.add.reduce(z, where=mask)
请注意,它不限于方阵:
>>> sum_antidiagonals(np.arange(15).reshape(5,3))
array([ 0, 4, 12, 21, 30, 24, 14])
说明
为了了解其工作原理,让我们通过一个示例来检查这些 strip 数组。
给定一个初始数组a,即(3, 2):
a = np.arange(6).reshape(3, 2)
>>> a
array([[0, 1],
[2, 3],
[4, 5]])
# after calculating z in the function
>>> z
array([[0, 1, 2, 3],
[1, 2, 3, 4],
[2, 3, 4, 5]])
你可以看到,这几乎就是我们想要的sum(axis=0),除了下三角形和上三角形是不需要的。我们真正想要总结的是:
array([[0, 1, -, -],
[-, 2, 3, -],
[-, -, 4, 5]])
输入掩码,我们可以从一维内核开始构建它:
kern = np.r_[np.repeat(False, r-1), np.repeat(True, c), np.repeat(False, r-1)]
>>> kern
array([False, False, True, True, False, False])
我们使用一个有趣的切片:(1, 1),这意味着我们重复同一行,但每次滑动一个元素:
>>> np.lib.stride_tricks.as_strided(
... kern, shape=(r, c+r-1), strides=(1, 1), writeable=False)
array([[False, False, True, True],
[False, True, True, False],
[ True, True, False, False]])
然后我们只需向左/向右翻转,并将其用作 np.add.reduce() 的 where 参数。
速度
b = np.random.normal(size=(1000, 1000))
# check equivalence with the OP's fast() function:
>>> np.allclose(fast(b), sum_antidiagonals(b))
True
%timeit sum_antidiagonals(b)
# 1.83 ms ± 840 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%timeit fast(b)
# 2.07 ms ± 15.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
在本例中,速度会快一点,但仅快 10% 左右。
在 300x300 数组上,sum_antidiagonals() 比 fast() 快 2.27 倍。
但是!
尽管将 z 和 mask 放在一起非常快(np.add.reduce() 之前的整个设置只需要 46 µs在上面的 1000x1000 示例中),求和本身为 O[r (r+c)],即使只有 O[r c] 实际相加(其中 mask == True) 是必需的。因此,方形数组的操作量增加了大约 2 倍。
在 10K x 10K 阵列上,这符合我们的要求:
快速需要 95 毫秒,而sum_antidiagonals需要 208 毫秒。
尺寸范围比较
我们将使用可爱的 perfplot包通过 n 范围比较多种方法的速度:
perfplot.show(
setup=lambda n: np.random.normal(size=(n, n)),
kernels=[just_sum_0, fast, fast_g, nb_fast_i, nb_fast_ij, sum_antidiagonals],
n_range=[2 ** k for k in range(3, 16)],
equality_check=None, # because of just_sum_0
xlabel='n',
relative_to=1,
)
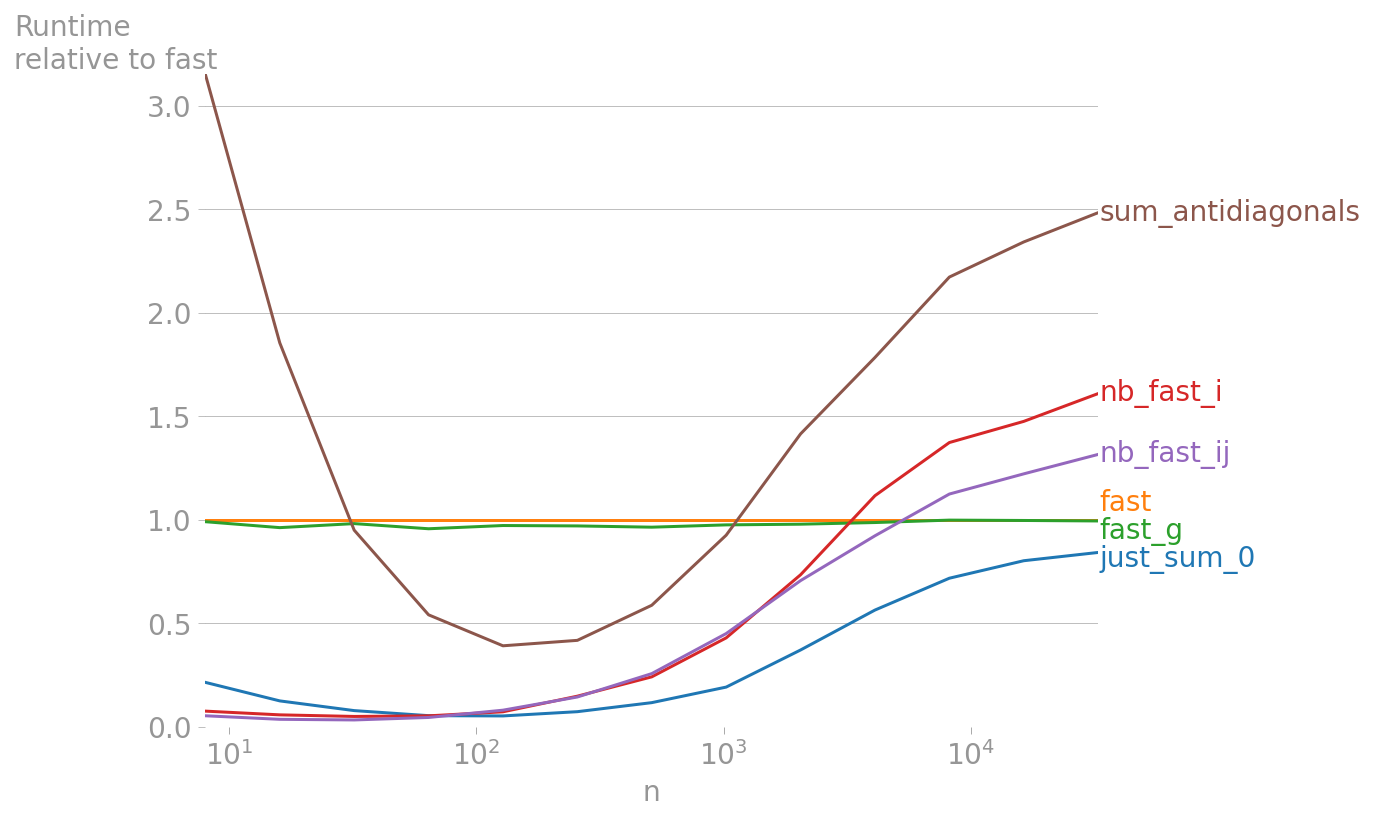
观察
- 如您所见,
sum_antidiagonals()相对于fast()的速度优势仅限于大约在 30 到 1000 之间的n范围. - 它永远不会打败
numba版本。 just_sum_0(),它只是沿axis=0求和(因此是一个很好的底线基准,几乎不可能被击败),只是稍微快一点对于大型阵列。这一事实表明fast()与大型数组的速度差不多。- 令人惊讶的是,
numba在达到一定大小后(即在最初几次运行“烧入”LLVM 编译之后)会减少。我不确定为什么会出现这种情况,但它似乎对于大型数组变得很重要。
其他函数的完整代码
(包括fast到非方形数组的简单推广)
from numba import njit
@njit
def nb_fast_ij(a):
# numba loves loops...
r, c = a.shape
z = np.zeros(c + r - 1, dtype=a.dtype)
for i in range(r):
for j in range(c):
z[i+j] += a[i, j]
return z
@njit
def nb_fast_i(a):
r, c = a.shape
z = np.zeros(c + r - 1, dtype=a.dtype)
for i in range(r):
z[i:i+c] += a[i, :]
return z
def fast_g(a):
# generalizes fast() to non-square arrays, also returns the same dtype
r, c = a.shape
z = np.zeros(c + r - 1, dtype=a.dtype)
for i in range(r):
z[i:i+c] += a[i]
return z
def fast(A):
# the OP's code
n = A.shape[0]
retval = np.zeros(2*n-1)
for i in range(n):
retval[i:(i+n)] += A[i, :]
return retval
def just_sum_0(a):
# for benchmarking comparison
return a.sum(axis=0)
关于python - 对具有滞后的列求和的最快方法,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/67336482/