我创建了一个要分配给某些表格的标题列表,如下所示:
title <- c('P3(400-450).FCz', 'P3(400-450).Cz', 'P3(400-450).Pz',
'LPPearly(500-700).FCz', 'LPPearly(500-700).Cz',
'LPPearly(500-700).Pz', 'LPP1(500-1000).FCz',
'LPP1(500-1000).Cz', 'LPP1(500-1000).Pz',
'LPP2(1000-1500).FCz', 'LPP2(1000-1500).Cz',
'LPP2(1000-1500).Pz', 'LPP2(1000-1500).POz')
list_1 <- paste0('lsmeans statics of ', title)
list_2 <- paste0('Contrasts of ', title)
titles_tables <-append(list_1, list_2)
如果我尝试运行以下代码来赋予正确的标题(实际上应该返回 13 个表,分别用于 lsmeans 统计和对比)
tables <- md %>% map(~.x %>%
map(~broom::tidy(.x) %>% flextable::flextable() %>%
colformat_double(digits = 2) %>% theme_box() %>%
valign(valign = "center") %>% autofit() %>%
set_caption(caption = titles_tables)))
我发现每个表仅显示第一个 title_tables 列表元素的名称。有人知道我可以对每个表的名称进行正确排序吗?
数据集是
> dput(head(out_long, 100))
structure(list(ID = c("01", "01", "01", "04", "04", "04", "06",
"06", "06", "07", "07", "07", "08", "08", "08", "09", "09", "09",
"10", "10", "10", "11", "11", "11", "12", "12", "12", "13", "13",
"13", "15", "15", "15", "16", "16", "16", "17", "17", "17", "18",
"18", "18", "19", "19", "19", "21", "21", "21", "22", "22", "22",
"23", "23", "23", "25", "25", "25", "27", "27", "27", "28", "28",
"28", "30", "30", "30", "44", "44", "44", "46", "46", "46", "49",
"49", "49", "01", "01", "01", "04", "04", "04", "06", "06", "06",
"07", "07", "07", "08", "08", "08", "09", "09", "09", "10", "10",
"10", "11", "11", "11", "12"), GR = c("RP", "RP", "RP", "RP",
"RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP",
"RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP",
"RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP",
"RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP",
"RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP",
"RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP",
"RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP",
"RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP",
"RP", "RP", "RP", "RP", "RP", "RP", "RP", "RP"), SES = c("V",
"V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V",
"V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V",
"V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V",
"V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V",
"V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V",
"V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V",
"V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V", "V",
"V", "V", "V", "V", "V", "V", "V", "V"), COND = c("NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR", "NEG-NOC", "NEU-NOC", "NEG-CTR",
"NEG-NOC", "NEU-NOC", "NEG-CTR"), signals = c("P3FCz", "P3FCz",
"P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz",
"P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz",
"P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz",
"P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz",
"P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz",
"P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz",
"P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz",
"P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz",
"P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz",
"P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz", "P3FCz",
"P3FCz", "P3FCz", "P3FCz", "P3Cz", "P3Cz", "P3Cz", "P3Cz", "P3Cz",
"P3Cz", "P3Cz", "P3Cz", "P3Cz", "P3Cz", "P3Cz", "P3Cz", "P3Cz",
"P3Cz", "P3Cz", "P3Cz", "P3Cz", "P3Cz", "P3Cz", "P3Cz", "P3Cz",
"P3Cz", "P3Cz", "P3Cz", "P3Cz"), value = c(-11.6312151716924,
-11.1438413285935, -3.99591470944713, -0.314155675382471, 0.238885648959708,
5.03749946898385, -0.213621915029167, -2.96032491743069, -1.97168681693488,
-2.83109425298642, 1.09291198163802, -6.692991645215, 4.23849942428043,
2.9898889629932, 3.5510699900835, 9.57481668808606, 5.4167795618285,
1.7067607715475, -6.13036076093477, -2.82955734597919, -2.50672211111696,
0.528517585832501, 8.16418133488309, 1.88777321897925, -7.73588468896919,
-9.83058052401056, -6.97442700196932, 1.27327945355082, 2.11962397764132,
0.524299677616254, -1.83310726842883, 0.658810483381172, -0.261373488428192,
4.37524298634374, 0.625555654900511, 3.19617639836154, 0.0405517582137798,
-3.29357103412113, -0.381435057304614, -5.73445509910268, -6.1129152355645,
-2.45744234877604, 2.95352732001065, 0.527721249096473, 1.91803490989119,
-3.46703346467546, -2.40438419043702, -5.35374408162217, -7.27028665849262,
-7.1532211375959, -5.39955520296854, 2.65765002364624, 0.372495441513391,
6.24433066412776, 1.85698518142405, -0.564454675803529, -0.068523080368053,
-7.04782633579147, -4.52263283590558, -6.62134671432544, 4.56661945182626,
3.05859761335498, 2.02997952225347, -6.10523962206958, -0.521871236969702,
-3.97851995684846, -2.61258020387919, -4.13974828699279, -3.9210032516844,
-4.63162466544638, -4.36762718685405, -6.71005969834916, -4.22719611676328,
-0.229916506217565, -5.69725200870146, -5.16524399006139, -5.53112490175437,
0.621502123415388, 2.23100741241039, 3.96990710862955, 7.75899775608441,
-1.30019374375434, -3.59899040898949, -1.92340529575071, 2.19344184533265,
5.87900720863083, -5.92378937757888, 2.44958531767688, 3.10043497883256,
1.65779442628225, 13.7118233181713, 6.86178446511352, 5.31481098188172,
-4.13240668697805, 0.162182285588285, 0.142083484505352, 5.42592103255673,
14.5496375672716, 4.52018125654081, -2.40677805475299)), row.names = c(NA,
-100L), class = c("tbl_df", "tbl", "data.frame"))
>
这是我获取 lsmeans 统计数据的方式,表格引用了这些数据:
md1 <- out_long %>%
group_by(signals) %>%
do(fit = lmerTest::lmer(value ~ COND + (1 |ID), data = .)) %>%
pull(fit) %>%
lapply(., function(m) lsmeans(m, pairwise ~ COND, adjust="tukey"))
最佳答案
考虑将append更改为
titles_tables <- Map(c, list_1, list_2)
as append 将两个列表连接成一个向量,而我们需要用 list_1 的每个对应元素来命名嵌套的 list 元素> 和 list_2。因此,最好通过连接相应的元素将其保留在向量列表中。
然后使用map2(如评论中所述)。在这里,它是一个嵌套列表。因此,我们需要两个map2。即第一个 map2 获取“md1”和相应的 titles_tables 列表,在下一个 map2 中,它将循环遍历相应的单个元素
library(dplyr)
library(purrr)
library(flextable)
library(emmeans)
output <- md1 %>%
map2(titles_tables[seq_along(md1)], ~{
title <- .y
.x %>%
map2(title, ~broom::tidy(.x) %>% flextable::flextable() %>%
colformat_double(digits = 2) %>% theme_box() %>%
valign(valign = "center") %>% autofit() %>%
set_caption(caption = .y))
})
-检查输出
output[[1]]$lsmeans
output[[1]]$contrasts


Rmarkdown 打印将是
---
title: "Title"
output:
html_document: default
word_document: default
pdf_document: default
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
```
```{r, echo = FALSE}
suppressPackageStartupMessages(library(dplyr))
suppressPackageStartupMessages(library(purrr))
suppressPackageStartupMessages(library(flextable))
suppressPackageStartupMessages(library(emmeans))
# sample data
title <- c('P3(400-450).FCz', 'P3(400-450).Cz', 'P3(400-450).Pz',
'LPPearly(500-700).FCz', 'LPPearly(500-700).Cz',
'LPPearly(500-700).Pz', 'LPP1(500-1000).FCz',
'LPP1(500-1000).Cz', 'LPP1(500-1000).Pz',
'LPP2(1000-1500).FCz', 'LPP2(1000-1500).Cz',
'LPP2(1000-1500).Pz', 'LPP2(1000-1500).POz')
list_1 <- paste0('lsmeans statics of ', title)
list_2 <- paste0('Contrasts of ', title)
titles_tables <-titles_tables <- Map(c, list_1, list_2)
md1 <- out_long %>%
group_by(signals) %>%
do(fit = lmerTest::lmer(value ~ COND + (1 |ID), data = .)) %>%
pull(fit) %>%
lapply(., function(m) lsmeans(m, pairwise ~ COND, adjust="tukey"))
output <- md1 %>% map2(titles_tables[seq_along(md1)], ~{
title <- .y
.x %>%
map2(title, ~broom::tidy(.x) %>% flextable::flextable() %>%
colformat_double(digits = 2) %>% theme_box() %>%
valign(valign = "center") %>% autofit() %>%
set_caption(caption = .y))
})
```
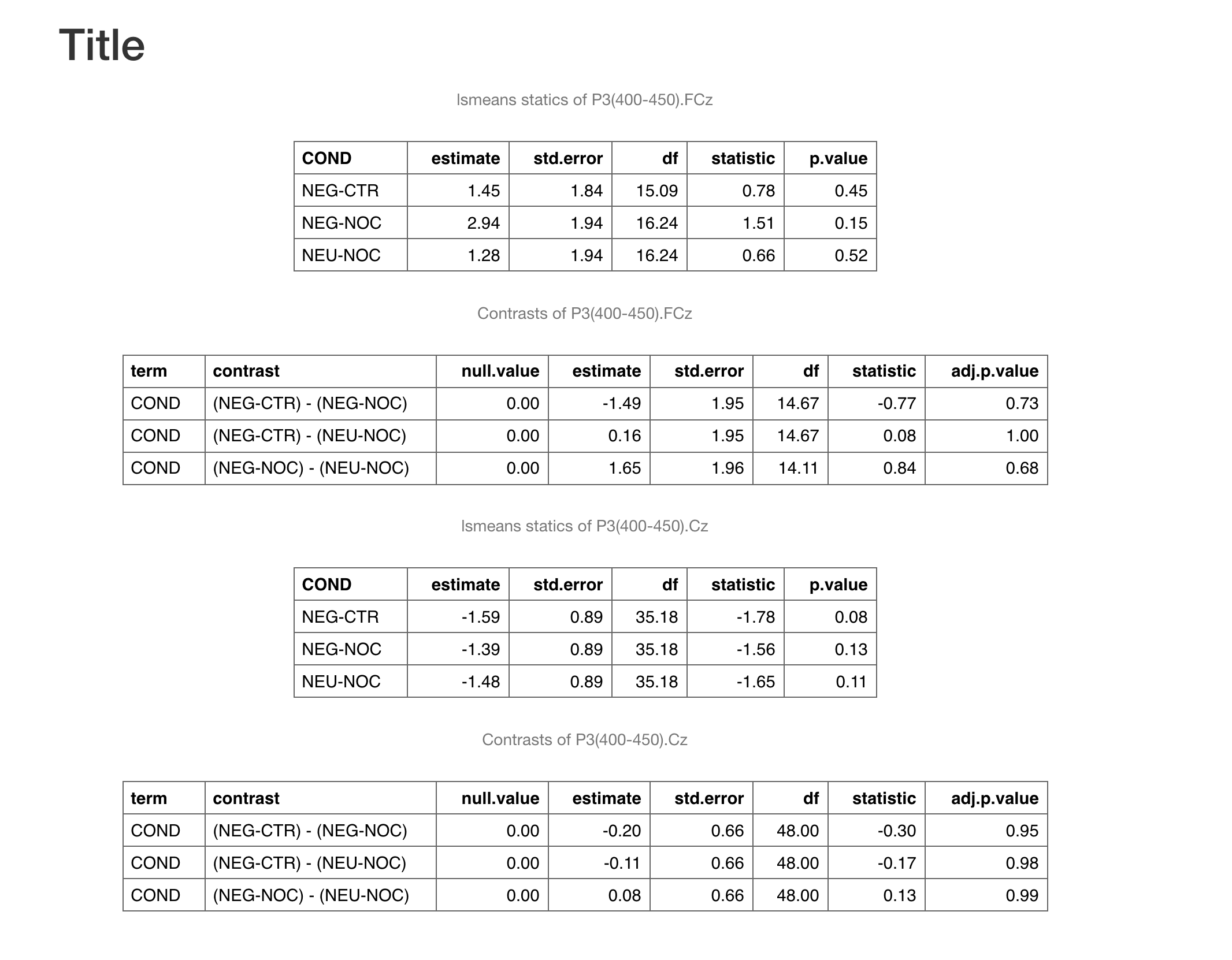
```{r model out, echo = FALSE, results = 'asis'}
for(i in seq_along(output)) {
cat(knitr::knit_print(output[[i]]$lsmeans))
cat(knitr::knit_print(output[[i]]$contrasts))
}
```
-输出
关于r - 重申弹性表的表分配,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/69843422/