我将“Key_Phrases”作为 pandas 数据框 df 中的一列。目标是根据语义相似性对它们进行聚类。我正在使用 SentenceTransformer 模型。
df['Key Phrases'] is as follows
'Key_Phrases'
0 ['BYD' 'Daiwa Capital Markets analyst' 'NIO' 'Order flows'\n 'consumer preferences' 'cost pressures' 'raw materials'\n 'regulatory pressure' 'sales cannibalization' 'sales volume growth'\n 'vehicle batteries']
1 ['CANADA' 'Canada' 'Global Carbon Pricing Challenge'\n 'Major Economies Forum' 'climate finance commitment'\n 'developing countries' 'energy security' 'food security'\n 'international shipping' 'pollution pricing']
2 ['Clean Power Plan' 'EPA' 'Environmental Protection Agency'\n 'Supreme Court' 'Supreme Court decision' 'Virginia' 'West Virginia'\n 'renewable energy' 'tax subsidies']
3 ['BlueOvalSK' 'Ford' 'Ford Motor' 'Kathleen Valley' 'LG Energy' 'Liontown'\n 'Liontown Resources' 'SK Innovation' 'SK On' 'Tesla' 'battery metals'\n 'joint venture' 'lithium spodumene concentrate'\n 'lithium supply agreement']
4 ['Emissions Trading System' 'European Commission' 'European Parliament'\n 'ICIS' 'carbon border adjustment mechanism' 'carbon leakage']
5 ['Digital Industries' 'MG Motor India' 'MindSphere'\n 'Plant Simulation software' 'Siemens' 'carbon footprints'\n 'digitalisation' 'experience' 'intelligent manufacturing'\n 'production efficiency' 'strategic collaborations']
6 ['Malaysia' 'Mosti' 'NTIS' 'National Technology and Innovation Sandbox'\n 'National Urbanisation Policy' 'Sunway Innovation Labs'\n 'Sunway iLabs Super Accelerator' 'economic growth'\n 'memorandum of understanding' 'quality of life' 'safe environment'\n 'smart cities' 'smart city sandbox' 'urban management' 'urban population']
7 ['Artificial Intelligence' 'Electricity and Water Authority'\n 'Green Mobility' 'Grid Automation' 'Internet of Things' 'Smart Dubai'\n 'Smart Energy Solutions' 'Smart Grid' 'Smart Water'\n 'artificial intelligence' 'blockchain' 'connected services'\n 'energy storage' 'integrated systems' 'interoperability' 'smart city'\n 'smart grid' 'sustainability' 'water network']
8 ['Artificial Intelligence' 'Clean Energy Strategy 2050'\n 'Dubai Electricity and Water Authority' 'Green Mobility'\n 'Grid Automation' 'Internet of Things' 'Smart Dubai'\n 'Smart Energy Solutions' 'Smart Grid' 'Smart Water'\n 'Zero Carbon Emissions Strategy' 'artificial intelligence' 'blockchain'\n 'clean energy sources' 'connected services' 'energy storage'\n 'integrated systems' 'interoperability' 'smart city' 'smart grid'\n 'sustainability']
Key_Phrases_list_1 = df['Key Phrases'].tolist()
from sentence_transformers import SentenceTransformer, util
import numpy as np
model = SentenceTransformer('distilbert-base-nli-stsb-quora-ranking')
#Encoding is done with one simple step
embeddings = model.encode(Key_Phrases_list_1, show_progress_bar=True, convert_to_numpy=True)
然后创建以下函数:
def detect_clusters(embeddings, threshold=0.90, min_community_size=20):
# Compute cosine similarity scores
cos_scores = util.pytorch_cos_sim(embeddings, embeddings)
#we filter those scores according to the minimum community size we specified earlier
# Minimum size for a community
top_k_values, _ = cos_scores.topk(k=min_community_size, largest=True)
# Filter for rows >= min_threshold
extracted_communities = []
for i in range(len(top_k_values)):
if top_k_values[i][-1] >= threshold:
new_cluster = []
# Only check top k most similar entries
top_val_large, top_idx_large = cos_scores[i].topk(k=init_max_size, largest=True)
top_idx_large = top_idx_large.tolist()
top_val_large = top_val_large.tolist()
if top_val_large[-1] < threshold:
for idx, val in zip(top_idx_large, top_val_large):
if val < threshold:
break
new_cluster.append(idx)
else:
# Iterate over all entries (slow)
for idx, val in enumerate(cos_scores[i].tolist()):
if val >= threshold:
new_cluster.append(idx)
extracted_communities.append(new_cluster)
unique_communities = []
extracted_ids = set()
for community in extracted_communities:
add_cluster = True
for idx in community:
if idx in extracted_ids:
add_cluster = False
break
if add_cluster:
unique_communities.append(community)
for idx in community:
extracted_ids.add(idx)
return unique_communities
然后调用该函数:
clusters = detect_clusters(embeddings, min_community_size=6, threshold=0.75)
我没有得到任何返回。我是否遗漏了 detector_clusters 函数中的任何内容。
最佳答案
由于OP要求一个自动选择集群数量的解决方案,因此使用像sklearn这样更强大的东西会更容易:
from sentence_transformers import SentenceTransformer, util
import numpy as np
model = SentenceTransformer('distilbert-base-nli-stsb-quora-ranking')
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
def choose_classifier(X):
X1 = X / (X**2).sum(axis=-1, keepdims=True)
vv = []
cc = np.arange(2, len(X))
for nclusters in cc:
km_model = KMeans(nclusters).fit(X1)
labels = km_model.labels_
v = silhouette_score(X1, labels)
vv.append(v)
nclusters = cc[np.argmax(vv)]
return KMeans(nclusters).fit(X1)
像这样使用
phrases = [
'I like ice cream',
'I like cake',
'You are so kind',
'You are very intelligent'
]
embeddings = model.encode(phrases, show_progress_bar=True, convert_to_numpy=True)
classifier = choose_classifier(embeddings)
for i, (v, s) in enumerate(zip(embeddings, phrases)):
print(classifier.predict(v[np.newaxis]), s)
[1] I like ice cream
[1] I like cake
[0] You are so kind
[0] You are very intelligent
支持 GPU 的解决方案
乍一看,我无法理解您在代码中所做的所有事情,但让我建议您一些简化的方法。我用pytorch_kmeans ,我探索了欧氏距离平方为 dot(A-B,A-B) = dot(A,A) + dot(B,B) - 2 * dot(A, B) 的事实。 ,余弦相似度为 dot(A, B) / sqrt(dot(A,A) * dot(B,B)) 。所以(1)
乘法A或B通过标量不会改变余弦相似度,(2) if A和B具有相同的长度,最小化欧几里德可以最大化余弦相似度。给定要聚类的向量集,您可以 (1) 对所有向量进行归一化,使它们具有相同的长度,(2) 计算使欧几里德距离最小化的聚类。然后你就得到了最大化余弦相似度的簇。
pip install kmeans_pytorch
设置
由于您没有提供数据,我将自己生成一个示例
import torch;
# 2D Example Data
# Generate some random data in three clusters
NPC=10
X = torch.cat([
(torch.randn((NPC, 2)) + c) * (torch.rand((NPC,1))**2+1)/2
for c in torch.tensor([[5,3], [-7,0], [-0, -7]])])
解决方案
这是代码
from kmeans_pytorch import kmeans
import torch
def detect_clusters(X, nclusters, tol=1e-6):
X = torch.as_tensor(X)
assert X.ndim == 2
# Project the points in a hypersphere
X1 = X / torch.sqrt(torch.sum(X**2, axis=-1, keepdims=True))
# Run kmeans on the normalized points with euclidean distance
cluster_ID, C = kmeans(X1, nclusters, distance='euclidean', tol=tol)
return cluster_ID, C
可视化示例
import matplotlib.pyplot as plt
import numpy as np
import torch;
#### THE RESUTLS ####
cluster_ID, C = detect_clusters(X, 3)
# Avoid distortion of the angles
plt.axes().set_aspect('equal')
# Initial points
plt.plot(X[:,0], X[:,1], '.')
# Reference circle
theta = torch.linspace(0, 2*np.pi, 1000)
plt.plot(torch.cos(theta), torch.sin(theta), '--k')
plt.plot(X1[:,0], X1[:,1], '.')
xlim = plt.xlim()
ylim = plt.ylim()
plt.xlim(xlim)
plt.ylim(ylim)
# Draw lines in the directions given by the centroids
R = 20
for c in C:
plt.plot([0, c[0]*R], [0, c[1]*R]);
plt.grid();
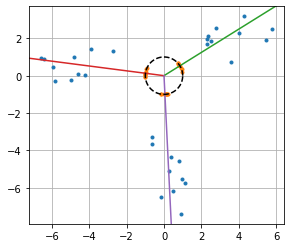
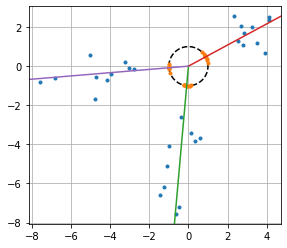
与句子嵌入一起使用
一些嵌入示例
from sentence_transformers import SentenceTransformer, util
import numpy as np
model = SentenceTransformer('distilbert-base-nli-stsb-quora-ranking')
phrases = [
'I like ice cream',
'I like cake',
'You are so kind',
'You are very intelligent'
]
embeddings = model.encode(phrases, show_progress_bar=True, convert_to_numpy=True)
然后您可以将嵌入传递到 detect_cluster我上面提供的功能
label, center = detect_clusters(torch.as_tensor(embeddings), 2)
for c, s in zip(label, phrases):
print(f'[{c}] {s}')
这应该给你相应集群的句子
[0] I like ice cream
[0] I like cake
[1] You are so kind
[1] You are very intelligent
关于python-3.x - 基于语义相似度的聚类不返回值,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/73183103/