提前致谢。
有了这些数据:
data <- structure(list(ID = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L,
5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L,
5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L,
5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L,
5L, 5L, 5L, 5L, 5L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L,
6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 7L, 7L, 7L,
7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L,
7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L,
7L, 7L, 7L), .Label = c("COL_P06", "COL_P07", "COL_P08", "COL_P09",
"COL_P10", "COL_P12", "COL_P13"), class = "factor"), PreyGen = structure(c(1L,
5L, 5L, 6L, 6L, 5L, 6L, 6L, 5L, 9L, 1L, 1L, 1L, 1L, 1L, 6L, 5L,
5L, 5L, 5L, 8L, 1L, 9L, 1L, 1L, 1L, 5L, 4L, 5L, 5L, 6L, 5L, 5L,
6L, 5L, 6L, 6L, 6L, 6L, 6L, 5L, 6L, 5L, 5L, 5L, 6L, 5L, 5L, 5L,
5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 6L, 5L, 6L, 5L, 5L, 5L, 5L,
6L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L,
5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 6L, 5L, 5L, 6L, 6L, 6L, 6L, 6L,
6L, 5L, 6L, 6L, 6L, 6L, 5L, 5L, 10L, 5L, 5L, 5L, 5L, 6L, 5L,
5L, 5L, 5L, 5L, 6L, 5L, 5L, 6L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L,
5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 6L, 5L, 5L, 5L, 5L, 4L, 5L,
5L, 5L, 6L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L,
5L, 5L, 4L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 6L, 5L, 5L, 5L, 5L,
5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 6L,
5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 6L, 5L, 5L, 6L, 5L, 5L, 5L,
5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 6L, 5L, 6L,
5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 4L, 5L, 4L, 5L, 5L, 5L, 5L, 6L,
4L, 5L, 5L, 3L, 5L, 5L, 5L, 2L, 5L, 10L, 5L, 5L, 5L, 4L, 3L,
5L, 5L, 5L, 5L, 5L, 5L, 6L, 4L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L,
5L, 6L, 5L, 5L, 1L, 6L, 5L, 5L, 5L, 6L, 5L, 5L, 5L, 5L, 5L, 5L,
5L, 1L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 6L, 1L, 6L, 6L, 1L, 6L,
6L, 1L, 5L, 10L, 5L, 5L, 5L, 5L, 1L, 5L, 5L, 5L, 5L, 5L, 5L,
5L, 6L, 5L, 6L, 5L, 6L, 5L, 5L, 5L, 5L, 5L, 5L, 5L), .Label = c("Beaver",
"Bird", "Bobcat", "Coyote", "Deer", "Elk", "No Kill", "Porcupine",
"Raccoon", "SmMamm"), class = "factor")), .Names = c("ID", "PreyGen"
), class = "data.frame", row.names = c(743L, 745L, 746L, 747L,
748L, 751L, 753L, 759L, 761L, 764L, 766L, 767L, 768L, 769L, 770L,
771L, 773L, 774L, 776L, 777L, 779L, 780L, 783L, 784L, 786L, 788L,
792L, 793L, 800L, 803L, 829L, 832L, 836L, 843L, 853L, 862L, 864L,
868L, 873L, 876L, 883L, 884L, 885L, 886L, 888L, 890L, 893L, 896L,
898L, 901L, 903L, 904L, 906L, 908L, 909L, 912L, 914L, 915L, 919L,
920L, 922L, 924L, 926L, 928L, 929L, 930L, 931L, 932L, 933L, 934L,
935L, 937L, 938L, 939L, 941L, 945L, 946L, 948L, 957L, 961L, 962L,
966L, 967L, 969L, 971L, 972L, 975L, 977L, 980L, 981L, 982L, 986L,
995L, 998L, 1000L, 1002L, 1007L, 1008L, 1016L, 1020L, 1025L,
1028L, 1031L, 1038L, 1043L, 1044L, 1047L, 1052L, 1062L, 1069L,
1072L, 1077L, 1078L, 1079L, 1080L, 1085L, 1093L, 1094L, 1095L,
1098L, 1100L, 1101L, 1102L, 1103L, 1104L, 1105L, 1107L, 1109L,
1110L, 1112L, 1114L, 1115L, 1116L, 1117L, 1120L, 1126L, 1132L,
1133L, 1146L, 1147L, 1151L, 1158L, 1160L, 1164L, 1166L, 1167L,
1169L, 1173L, 1175L, 1180L, 1181L, 1184L, 1190L, 1192L, 1193L,
1196L, 1198L, 1205L, 1208L, 1209L, 1213L, 1216L, 1218L, 1219L,
1224L, 1225L, 1227L, 1231L, 1232L, 1233L, 1234L, 1237L, 1240L,
1241L, 1242L, 1243L, 1244L, 1245L, 1246L, 1248L, 1249L, 1250L,
1253L, 1255L, 1257L, 1261L, 1262L, 1264L, 1271L, 1274L, 1275L,
1276L, 1277L, 1280L, 1282L, 1288L, 1290L, 1297L, 1299L, 1305L,
1307L, 1308L, 1309L, 1310L, 1315L, 1324L, 1327L, 1334L, 1335L,
1336L, 1340L, 1342L, 1343L, 1344L, 1345L, 1348L, 1349L, 1352L,
1355L, 1356L, 1357L, 1358L, 1360L, 1361L, 1363L, 1364L, 1365L,
1368L, 1373L, 1374L, 1377L, 1378L, 1381L, 1383L, 1385L, 1387L,
1388L, 1390L, 1391L, 1392L, 1393L, 1395L, 1397L, 1398L, 1404L,
1405L, 1408L, 1409L, 1410L, 1411L, 1412L, 1414L, 1417L, 1420L,
1425L, 1426L, 1431L, 1432L, 1433L, 1435L, 1441L, 1445L, 1446L,
1447L, 1448L, 1450L, 1451L, 1456L, 1458L, 1466L, 1468L, 1474L,
1475L, 1476L, 1478L, 1483L, 1486L, 1488L, 1489L, 1490L, 1491L,
1492L, 1495L, 1497L, 1499L, 1500L, 1501L, 1502L, 1504L, 1506L,
1509L, 1511L, 1514L, 1518L, 1520L, 1526L, 1533L, 1535L, 1537L,
1541L, 1542L, 1544L, 1547L, 1549L, 1551L, 1552L, 1553L, 1556L,
1557L, 1559L, 1560L, 1565L, 1567L, 1569L, 1571L, 1572L, 1573L,
1576L, 1578L, 1588L, 1590L, 1592L, 1593L, 1596L, 1598L, 1599L,
1601L, 1603L, 1605L, 1607L, 1612L))
其头部如下:
> head(data)
ID PreyGen
743 COL_P06 Beaver
745 COL_P06 Deer
746 COL_P06 Deer
747 COL_P06 Elk
748 COL_P06 Elk
751 COL_P06 Deer
和这段代码:
library(ggplot2)
ggplot(data, aes(PreyGen) ) +
geom_bar(position="dodge")+
facet_wrap(~ID,scales="free",ncol=2)
我可以制作这个情节
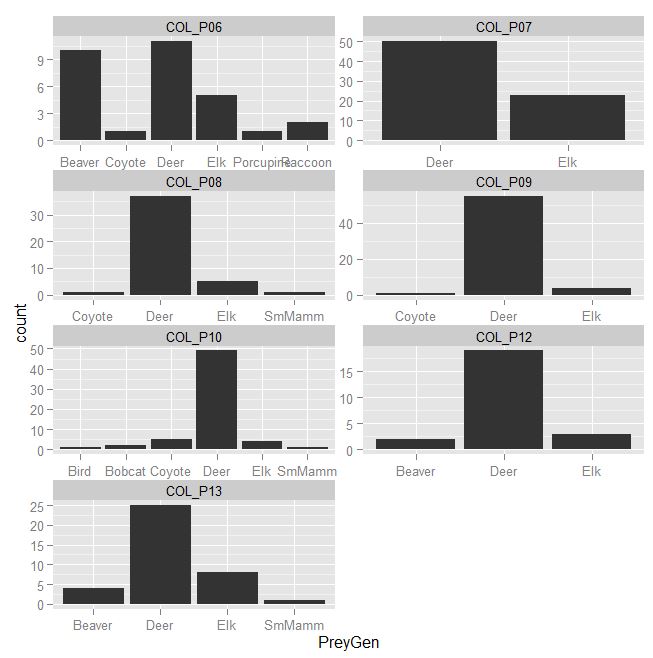
在上面的图中我想要:
1) 设置 x 轴,以便所有 ID 都包含所有 PreyGen。意味着每个 x 轴都应该具有 preyGen
2) 让 y 轴为比例而不是计数,并且所有 ID 的 y 轴具有相同的比例 (0 - 100%)
3)在空白处添加合并图。含义只是显示 PrenGen 的分布,而不是作为 ID 的函数。
就像这里,
ggplot(data, aes(PreyGen) ) +
geom_bar(position="dodge")
但作为上面组中的第七个图包含在内。
感谢您的建议和帮助!
最佳答案
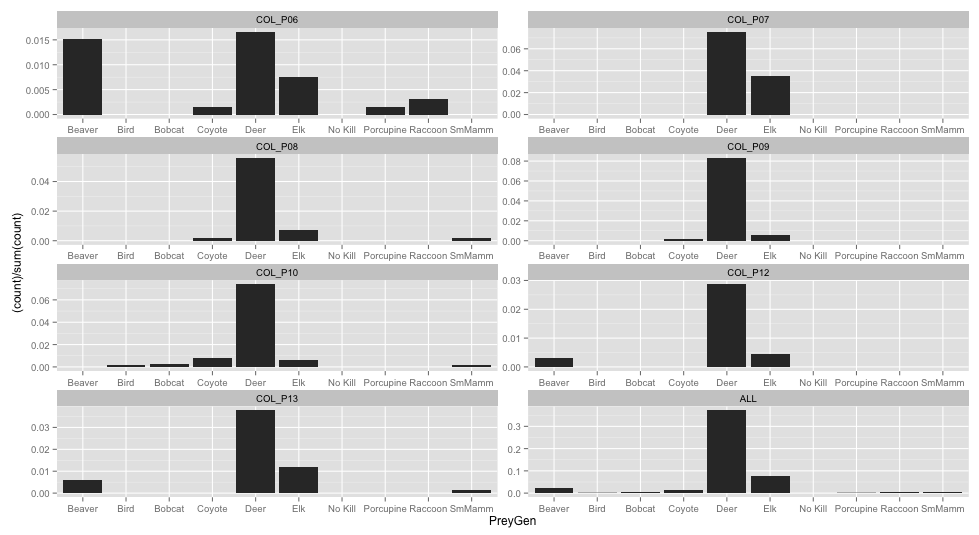
如果您想计算每个方面的分数,那么您必须单独计算统计数据(尽管很想知道是否有人知道如何直接执行此操作):
library(plyr)
data2 <- rbind(data, transform(data, ID="ALL"))
data3 <- ddply(data2, .(ID, PreyGen), summarise, PreyGenCount=length(PreyGen))
data3$PreyGenPct <- with(data3, ave(PreyGenCount, ID, FUN=function(x) x / sum(x) * 100))
ggplot(data3, aes(PreyGen)) +
geom_bar(aes(y=PreyGenPct), stat="identity") +
facet_wrap(~ID, ncol=2) +
scale_x_discrete(drop=F) +
coord_cartesian(ylim=c(0, 100))

我们使用 coord_cartesian 将 y 限制设置为您请求的内容,并使用 scale_x_discrete(drop=F) 确保所有级别均保留在所有方面。
如果您对总数的一小部分感到满意,那么您可以这样做:
ggplot(data2, aes(PreyGen) ) +
geom_bar(aes(y = (..count..)/sum(..count..))) +
facet_wrap(~ID,scales="free",ncol=2) +
scale_x_discrete(drop=F)
关于r - 在ggplot中使用 `facet_wrap`时如何修复x和y轴,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/22214050/