我在 R 中有一个二项式 GLM,其中有几个连续和分类的预测变量。
响应变量是“Presence”,它是二进制的 (0/1)。 长度是连续变量,而其他所有变量都是分类变量。
我正在尝试绘制最终模型中每个变量的预测,特别是“长度”,但我遇到了困难。
我的数据如下:
MyData<-structure(list(site = structure(c(3L, 1L, 3L, 2L, 1L, 4L, 3L,
4L, 1L, 2L, 4L, 5L, 5L, 1L, 4L, 3L, 2L, 4L, 1L, 4L, 5L, 1L, 5L,
4L, 3L, 1L, 3L, 5L, 5L, 4L, 4L, 3L, 1L, 5L, 1L, 3L, 1L, 4L, 4L,
3L, 4L, 4L, 2L, 3L, 1L, 4L, 2L, 1L, 1L, 4L, 4L, 4L, 1L, 3L, 3L,
2L, 1L, 4L, 2L, 5L, 5L, 3L, 3L, 2L, 5L, 2L, 4L, 5L, 2L, 4L, 4L,
2L, 5L, 2L, 3L, 5L, 4L, 4L, 5L, 1L, 1L, 3L, 2L, 4L, 3L, 1L, 4L,
3L, 1L, 4L, 3L, 3L, 4L, 5L, 1L, 3L, 2L, 3L, 2L, 3L, 2L, 1L, 1L,
5L, 5L, 1L, 5L, 2L, 3L, 4L, 4L, 3L, 2L, 3L, 3L, 5L, 3L, 3L, 3L,
5L, 1L, 5L, 2L, 3L, 4L, 5L, 5L, 1L, 4L, 2L, 5L, 3L, 2L, 5L, 4L,
3L, 3L, 3L, 1L, 1L, 4L, 1L, 2L, 4L, 5L, 1L, 1L, 2L, 2L, 5L, 3L,
4L, 4L, 1L, 5L, 2L, 4L, 3L, 1L, 1L, 3L, 2L, 1L, 3L, 4L, 3L, 1L,
5L, 3L, 3L, 3L, 4L, 1L, 1L, 3L, 4L, 3L, 1L, 1L, 1L, 1L, 5L, 1L,
3L, 4L, 3L, 2L, 1L, 1L, 2L, 5L, 2L, 1L, 5L, 3L, 1L, 4L, 1L, 3L,
3L, 3L, 3L, 5L, 1L, 4L, 1L, 1L, 3L, 3L, 4L, 1L, 3L, 3L, 4L, 2L,
5L, 5L, 5L, 1L, 4L, 4L, 3L, 1L, 2L, 3L, 1L, 3L, 1L, 1L, 4L, 3L,
1L, 1L, 5L, 3L, 1L), .Label = c("R1a", "R1b", "R2", "Za", "Zb"
), class = "factor"), species = structure(c(1L, 1L, 3L, 3L, 3L,
1L, 3L, 1L, 4L, 3L, 1L, 1L, 1L, 3L, 1L, 3L, 3L, 1L, 3L, 1L, 1L,
1L, 1L, 4L, 3L, 4L, 3L, 1L, 1L, 1L, 1L, 1L, 4L, 1L, 3L, 1L, 4L,
3L, 1L, 1L, 1L, 1L, 3L, 3L, 3L, 2L, 3L, 1L, 1L, 3L, 1L, 1L, 1L,
1L, 3L, 3L, 1L, 2L, 3L, 1L, 2L, 1L, 1L, 3L, 1L, 3L, 1L, 1L, 1L,
1L, 1L, 2L, 1L, 3L, 1L, 1L, 1L, 1L, 1L, 3L, 3L, 1L, 3L, 1L, 3L,
3L, 1L, 3L, 3L, 1L, 3L, 1L, 3L, 1L, 3L, 1L, 3L, 3L, 4L, 3L, 1L,
1L, 3L, 1L, 1L, 4L, 1L, 3L, 3L, 1L, 1L, 1L, 3L, 3L, 3L, 2L, 4L,
1L, 3L, 1L, 3L, 1L, 3L, 3L, 1L, 1L, 1L, 3L, 4L, 3L, 1L, 1L, 3L,
1L, 1L, 4L, 1L, 3L, 1L, 3L, 1L, 2L, 1L, 1L, 2L, 3L, 3L, 3L, 3L,
1L, 1L, 1L, 1L, 1L, 1L, 3L, 3L, 1L, 2L, 2L, 3L, 3L, 3L, 3L, 1L,
3L, 1L, 4L, 3L, 1L, 4L, 1L, 1L, 3L, 1L, 1L, 3L, 1L, 1L, 3L, 3L,
1L, 4L, 3L, 4L, 3L, 1L, 1L, 2L, 3L, 1L, 1L, 1L, 2L, 3L, 4L, 3L,
1L, 1L, 4L, 1L, 1L, 2L, 1L, 1L, 3L, 3L, 1L, 3L, 2L, 4L, 3L, 3L,
1L, 3L, 1L, 4L, 1L, 1L, 4L, 1L, 3L, 1L, 3L, 3L, 3L, 1L, 3L, 1L,
1L, 1L, 3L, 1L, 1L, 1L, 3L), .Label = c("Monogyna", "Other",
"Prunus", "Rosa"), class = "factor"), aspect = structure(c(4L,
4L, 4L, 4L, 4L, 3L, 4L, 3L, 4L, 4L, 3L, 4L, 4L, 4L, 3L, 3L, 4L,
3L, 4L, 3L, 1L, 4L, 4L, 3L, 2L, 4L, 4L, 4L, 4L, 3L, 3L, 4L, 4L,
4L, 4L, 2L, 4L, 3L, 3L, 1L, 3L, 3L, 4L, 4L, 4L, 3L, 4L, 4L, 4L,
3L, 3L, 3L, 4L, 1L, 3L, 4L, 4L, 3L, 4L, 4L, 4L, 3L, 3L, 4L, 1L,
4L, 3L, 4L, 4L, 3L, 3L, 4L, 4L, 4L, 4L, 1L, 3L, 3L, 4L, 4L, 4L,
2L, 4L, 3L, 3L, 4L, 3L, 4L, 4L, 3L, 4L, 3L, 3L, 4L, 4L, 3L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 1L, 4L, 4L, 4L, 4L, 4L, 3L, 3L, 4L, 4L,
3L, 2L, 3L, 1L, 2L, 5L, 2L, 4L, 4L, 4L, 3L, 3L, 1L, 2L, 4L, 3L,
4L, 4L, 3L, 4L, 4L, 3L, 4L, 4L, 3L, 4L, 4L, 3L, 4L, 4L, 3L, 1L,
4L, 4L, 4L, 4L, 4L, 4L, 3L, 3L, 4L, 4L, 4L, 3L, 4L, 4L, 4L, 4L,
4L, 4L, 3L, 3L, 3L, 4L, 4L, 3L, 4L, 2L, 3L, 4L, 4L, 2L, 3L, 2L,
4L, 4L, 4L, 4L, 4L, 4L, 3L, 3L, 3L, 4L, 4L, 4L, 4L, 4L, 4L, 4L,
4L, 2L, 4L, 3L, 4L, 4L, 4L, 3L, 4L, 4L, 4L, 3L, 4L, 4L, 4L, 3L,
3L, 4L, 2L, 5L, 3L, 4L, 2L, 4L, 4L, 4L, 3L, 3L, 3L, 4L, 4L, 2L,
4L, 3L, 4L, 4L, 3L, 4L, 4L, 4L, 3L, 2L, 4L), .Label = c("East",
"Flat", "North", "South", "West"), class = "factor"), length = c(260L,
60L, 60L, 40L, 240L, 80L, 30L, 100L, 100L, 200L, 70L, 50L, 60L,
35L, 120L, 60L, 500L, 40L, 20L, 70L, 250L, 80L, 50L, 130L, 350L,
170L, 50L, 60L, 90L, 50L, 40L, 110L, 60L, 70L, 70L, 500L, 140L,
50L, 50L, 360L, 50L, 150L, 60L, 270L, 280L, 130L, 130L, 50L,
60L, 30L, 70L, 70L, 60L, 400L, 20L, 30L, 70L, 160L, 340L, 100L,
210L, 60L, 70L, 130L, 50L, 40L, 50L, 80L, 390L, 40L, 110L, 130L,
40L, 230L, 120L, 70L, 80L, 80L, 90L, 70L, 150L, 120L, 50L, 100L,
120L, 10L, 40L, 80L, 180L, 160L, 200L, 40L, 70L, 90L, 50L, 40L,
80L, 80L, 70L, 480L, 90L, 60L, 100L, 140L, 190L, 20L, 70L, 360L,
70L, 130L, 60L, 50L, 320L, 210L, 130L, 180L, 90L, 20L, 300L,
90L, 50L, 130L, 70L, 70L, 40L, 40L, 50L, 40L, 100L, 20L, 70L,
100L, 340L, 70L, 110L, 40L, 230L, 200L, 80L, 35L, 110L, 200L,
50L, 110L, 100L, 50L, 150L, 110L, 50L, 50L, 40L, 70L, 80L, 60L,
100L, 90L, 40L, 300L, 140L, 180L, 140L, 40L, 190L, 100L, 170L,
40L, 120L, 15L, 70L, 340L, 40L, 40L, 70L, 60L, 130L, 140L, 170L,
120L, 90L, 130L, 210L, 50L, 180L, 120L, 100L, 50L, 90L, 70L,
360L, 80L, 30L, 170L, 70L, 300L, 40L, 130L, 120L, 90L, 40L, 40L,
140L, 80L, 400L, 70L, 80L, 60L, 420L, 320L, 200L, 40L, 50L, 70L,
50L, 80L, 50L, 110L, 100L, 120L, 170L, 20L, 110L, 20L, 20L, 30L,
30L, 90L, 150L, 80L, 40L, 90L, 300L, 30L, 70L, 50L, 90L, 200L
), sun = structure(c(1L, 1L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 1L,
3L, 3L, 3L, 3L, 1L, 1L, 1L, 3L, 3L, 3L, 3L, 2L, 3L, 1L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 1L, 1L, 3L, 3L, 3L, 3L, 1L, 3L, 3L, 1L, 3L,
3L, 1L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 1L, 3L, 3L, 3L,
3L, 2L, 1L, 1L, 3L, 3L, 3L, 3L, 3L, 3L, 1L, 3L, 3L, 1L, 2L, 1L,
1L, 3L, 3L, 3L, 2L, 3L, 3L, 2L, 3L, 3L, 1L, 3L, 3L, 3L, 1L, 3L,
1L, 3L, 3L, 2L, 1L, 3L, 3L, 1L, 1L, 3L, 1L, 3L, 3L, 1L, 1L, 1L,
2L, 1L, 1L, 3L, 3L, 1L, 1L, 1L, 3L, 2L, 1L, 3L, 1L, 1L, 3L, 3L,
1L, 1L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 2L, 3L, 1L, 1L, 1L,
3L, 3L, 3L, 1L, 3L, 3L, 1L, 3L, 3L, 1L, 3L, 3L, 1L, 3L, 3L, 3L,
3L, 1L, 3L, 1L, 3L, 1L, 1L, 3L, 3L, 3L, 1L, 3L, 3L, 3L, 1L, 1L,
1L, 1L, 3L, 3L, 1L, 1L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 1L, 1L,
3L, 3L, 3L, 3L, 2L, 1L, 1L, 1L, 3L, 3L, 3L, 3L, 3L, 3L, 1L, 2L,
3L, 3L, 3L, 3L, 3L, 1L, 1L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 2L, 1L,
1L, 3L, 3L, 3L, 3L, 1L, 3L, 1L, 3L, 3L, 3L, 1L, 1L, 3L, 3L, 2L,
3L, 3L), .Label = c("Half", "Shade", "Sun"), class = "factor"),
leaf = structure(c(2L, 2L, 4L, 2L, 2L, 2L, 2L, 2L, 4L, 2L,
2L, 4L, 4L, 4L, 2L, 2L, 2L, 4L, 4L, 2L, 2L, 4L, 2L, 2L, 1L,
2L, 2L, 4L, 2L, 4L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 4L, 2L,
2L, 2L, 2L, 1L, 2L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 4L, 2L,
2L, 4L, 1L, 2L, 4L, 1L, 2L, 4L, 2L, 4L, 2L, 2L, 2L, 1L, 4L,
4L, 1L, 4L, 1L, 2L, 4L, 3L, 2L, 2L, 2L, 2L, 4L, 2L, 4L, 2L,
2L, 2L, 2L, 2L, 4L, 1L, 2L, 4L, 2L, 2L, 2L, 2L, 2L, 2L, 1L,
1L, 4L, 2L, 2L, 1L, 4L, 2L, 2L, 2L, 1L, 4L, 2L, 2L, 1L, 1L,
1L, 2L, 4L, 2L, 1L, 2L, 2L, 2L, 2L, 2L, 4L, 2L, 2L, 2L, 2L,
4L, 2L, 2L, 4L, 1L, 2L, 2L, 1L, 2L, 2L, 2L, 1L, 2L, 2L, 1L,
2L, 2L, 1L, 2L, 2L, 2L, 2L, 4L, 2L, 2L, 2L, 4L, 4L, 1L, 1L,
2L, 2L, 2L, 1L, 1L, 1L, 1L, 4L, 2L, 2L, 2L, 4L, 2L, 2L, 2L,
1L, 1L, 2L, 1L, 2L, 2L, 4L, 2L, 2L, 2L, 2L, 2L, 4L, 1L, 2L,
4L, 2L, 2L, 1L, 2L, 2L, 4L, 2L, 4L, 4L, 2L, 2L, 1L, 2L, 2L,
2L, 2L, 4L, 1L, 1L, 2L, 1L, 2L, 2L, 2L, 1L, 4L, 1L, 1L, 2L,
1L, 2L, 2L, 2L, 4L, 2L, 2L, 2L, 2L, 2L, 2L, 4L, 2L, 4L, 2L,
2L), .Label = c("Large", "Medium", "Scarce", "Small"), class = "factor"),
Presence = c(0L, 0L, 1L, 0L, 0L, 0L, 1L, 0L, 0L, 0L, 0L,
0L, 0L, 1L, 1L, 1L, 0L, 1L, 1L, 0L, 0L, 0L, 0L, 0L, 0L, 0L,
1L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 1L, 0L, 0L,
1L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 1L, 1L, 0L, 0L, 0L, 0L, 1L,
0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 1L, 0L, 0L, 0L, 0L, 0L,
0L, 0L, 0L, 0L, 0L, 1L, 1L, 0L, 1L, 0L, 0L, 1L, 0L, 0L, 1L,
0L, 0L, 0L, 1L, 0L, 1L, 1L, 0L, 0L, 1L, 0L, 0L, 0L, 0L, 0L,
1L, 1L, 0L, 0L, 0L, 0L, 0L, 1L, 0L, 0L, 0L, 0L, 0L, 0L, 0L,
0L, 1L, 0L, 1L, 0L, 0L, 0L, 0L, 1L, 0L, 1L, 1L, 0L, 1L, 0L,
0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 1L, 1L, 0L, 0L, 1L, 0L, 1L,
0L, 0L, 1L, 0L, 0L, 0L, 0L, 1L, 0L, 0L, 1L, 0L, 0L, 0L, 0L,
1L, 0L, 0L, 0L, 1L, 0L, 0L, 0L, 0L, 0L, 0L, 1L, 1L, 0L, 0L,
0L, 1L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 1L, 0L, 0L, 0L,
0L, 1L, 0L, 1L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 1L,
0L, 0L, 0L, 0L, 0L, 1L, 0L, 0L, 0L, 1L, 0L, 0L, 0L, 0L, 0L,
1L, 1L, 0L, 1L, 0L, 0L, 0L, 1L, 0L, 0L, 1L, 1L, 0L, 1L, 0L
)), .Names = c("site", "species", "aspect", "length", "sun",
"leaf", "Presence"), row.names = c(NA, 236L), class = "data.frame")
(请注意,这是一个缩减的数据集,我已经删除了模型选择期间删除的变量)
最佳模型是:
model <- glm(Presence ~ site + species + aspect + length + sun
+ leaf, data=MyData, family=binomial)
我尝试了以下操作,但它也需要其他变量,所以我收到错误:
plot(MyData$length, MyData$Presence)
mydat1 <- data.frame(length = seq(from = 10, to = 500, by = 1)
pred1 <- predict(model, newdata = mydat1, type = "response")
lines(MyData$length, pred1)
所以我尝试指定所有变量,但它只在存在数据点上放置一条水平线(这意味着我需要指定我认为的因子变量的所有可能组合):
plot(MyData$length, MyData$Presence)
mydat2 <- data.frame(length = seq(from = 10, to = 500, by = 1),
site = "R1a",
species = "Monogyna",
aspect = "Flat",
sun = "Sun",
leaf = "Scarce")
pred2 <- predict(model, newdata = mydat2, type = "response")
lines(MyData$length, pred2)
最后,我尝试了以下代码:
pred <- predict(model, type = "response")
par(mfrow=c(2,2))
for(i in names(MyData)){
plot(MyData[,i],pred,xlab=i, ylab="Probability")
}
我对最后一个感到困惑,因为我无法获得曲线,而且输出为我提供了甚至不在最佳模型中的变量的预测值。
我想,在这个模型下,我应该期望的是一条正弦曲线。但这不是我得到的。
如何生成有意义的预测图?
任何帮助将不胜感激。
最佳答案
我会使用 effects 包为单个预测器提供一些更简单的结果。方法如下:
library(effects)
fit <- as.data.frame(effect('length', model, xlevels = 100))
绘图很容易(尽管注意过度绘图):
plot(MyData$length, MyData$Presence)
lines(fit$length, fit$fit)
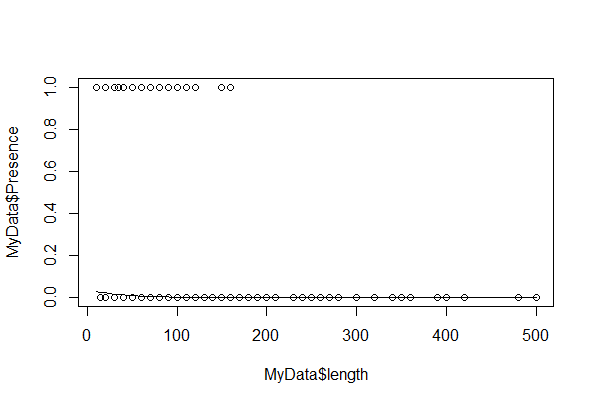
或者我们可以使用ggplot2:
library(ggplot2)
ggplot() +
geom_count(aes(length, Presence), MyData) +
geom_line(aes(length, fit), fit, size = 1, col = 'red') +
geom_ribbon(aes(length, ymin = lower, ymax = upper), fit, alpha = 0.15) +
scale_size_area()
我们可以看到长度的影响不是很明显。
关于r - 如何绘制同时具有连续变量和分类变量的二项式 GLM 的预测,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/42191567/